前端埋点(一)
背景
我们是做NPMD工具的,但是对自身的产品本身确没有监控,说起来就很惆怅了,当然主要原因还是产品从0到1这个过程,前期放荡不羁的功能造作,导致对基础设施建设这块做的很少。
这是一贯坚持基础建设重要性的我的又一篇分享。关于前端埋点。
所以我当然承认基础建设是体系化的漫长的一个过程,但是因为各种不可抗因素,现没法体系化落地,所以只能先捡最能产生价值的且能引起更多不同之能的同事关注的事开始做,比如前端埋点。
先说痛点:
整个质量体系监控缺失,前端报错后端报错,全靠经验、人肉日志和用户主动反馈。
特别是现场问题排查,通常都会先找到前端定位问题,现场又不能远程。
业务数据的效果无从跟踪。
如使用某功能的频率无从得知,需要人肉从客户处拿此类数据,且还不准。
用户的访问行为/设备特征/应用性能信息完全无感知。
如活跃时间点(避开做升级),软硬件系统和设备比例(做兼容),慢页面优化等无从做起。
前端埋点对我们产品的好处:
记录访问行为/设备特征/应用性能信息。
为产品的设计,提供参考数据,对于我们这种从0到1的ToB产品,我个人觉得是特别需要这类用户反馈数据的,避免闭门造车。
为产品的优化(性能、产品设计…)提供参考。
记录异常。
便于问题的排查,我们处理的问题一般是客户现场问题,通常情况下又都是客户的内网,所以是无法远程的,这类异常记录手段刚好能丰富异常记录数据,便于问题的排查。
所以可以看出,前端埋点至少会影响的到产品、UCD、研发、测试,当利益方多的时候,事情才更有推下去的可能性。
埋点
决策源于数据,而数据源于采集,采集源于规则梳理,让这一切发生源于工程师的创造力和执行力。
埋点的方式
手动埋点
手动代码埋点比较常见,即需要在采集数据的地方调用埋点的方法。
优点是流量可控,业务方可以根据需要在任意地点任意场景进行数据采集,采集信息也完全由业务方来控制。这样的有点也带来了一些弊端,需要业务方来写死方法,如果采集方案变了,业务方也需要重新修改代码,重新发布。
百度统计等第三方数据统计服务商大都采用这种方案;
可视化埋点
即通过可视化工具配置采集节点,在前端自动解析配置并上报埋点数据。
优点业务方工作量少,缺点则是技术上推广和实现起来有点难(业务方前端代码规范是个大前提,比如唯一ID等)。
代表方案是已经开源的Mixpanel;
“无痕埋点”
无痕埋点则是前端自动采集全部事件,上报埋点数据,由后端来过滤和计算出有用的数据,优点是前端只要加载埋点脚本。缺点是流量和采集的数据过于庞大,服务器性能压力山大,主流的 GrowingIO 就是这种实现方案。
那我们产品现阶段比较适合的方式时什么呢?
手动代码埋点的方案,代码埋点虽然使用起来灵活,但是开发成本较高且对业务代码有强侵入性,并且一旦发布就很难修改,更何况我们这是部署在客户现场的。
可视化埋点也是不太可行的,我们连工程化、规范化都没做到,而且是部署在客户现场的,先天不足,再一个可视化埋点通常基于xpath的方式,只能读取页面上标签元素展示出来的属性,不能够获取上下文(通常内存里)的一些属性。而且页面的结构发生变化时,需重新标记操作。
所以几乎只有考虑无痕埋点,虽然无痕埋点流量消耗和数据计算成本很高,但是因为我们是ToB运维工具,企业内部用的,使用人数也不多,所以也还好,当然这是第一版如果确实在实验局发现压力挺大,我们可以再改进一下,比如采用手动埋点+无痕埋点的方式或者三种结合的方式。
OK先把埋点方式定下来了,我们现在考虑剩下的东西。
埋点需求整理原则
埋点不能乱埋,埋点的原则是基于一系列问题展开,并基于这些问题确定埋点需求,怎么确定埋点需求,可以照下面的问题切入进行梳理
HOW:
- 怎样证明新功能效果?
- 需要哪些埋点?我们要采集什么内容,进行哪些采集接口的约定?
- 我该怎么埋这些点?
- 部分埋点的计算逻辑是什么?
- 数据结果怎么看?
- 通过什么方式来调用我们的采集脚本?
- 无埋点:考虑到数据量对于服务器的压力,我们需要对无埋点进行开关配置,可以配置进行哪些元素进行无埋点采集
WHO:
- 我的产品设计面对的用户群里是谁?
- 用户特征是什么?
- 这部分特征用户对功能预期的数据结果是什么?
- 用户习惯是什么?
WHAT:
- 产品包含哪几个模块?
WHERE:
- 新功能展示在产品端的哪个位置?
- 在哪些版本生效?
- 哪些功能的展示或作用在哪里需要跟服务端等交互?
WHEN:
- 功能是在用户场景什么时候调用产生?
- 调用过程中什么时候和服务端交互?
- 功能调用正常情况下需要大概需要多长时间?
- 什么情况会影响调用结果?
- 调用有风险的时候,是否需要加监测?
回答了上面的问题,基本上能知道埋点的意义在哪儿以及需要收集哪些数据等,接下来就得开始指定埋点规范了。
埋点规范
埋点规范就跟编码规范一样,不按照规范就会有很大的隐患比如以下问题:
埋点混乱
常常埋错,漏埋
业务变化后,老埋点数据失去意义
埋点数据无人使用,浪费资源
数据团队、研发团队、产品团队协作配合难度大
很多时候不太重视数据,而是重视业务的快速上线
埋点语义不明确,同一个按钮存在多种描述,不易检索
无用/重复埋点太多,干扰了正常埋点数据
大量存量埋点Owner离职或者转岗,导致大量僵尸埋点信息
所以为了避免以上问题我们需要建立一个好的规范,比如命名规范和流程规范。
埋点命名规范
我们当前的做法是埋点名称只能是由字母、数字、下划线组成,并保证在应用内唯一,比如sw是展示,ck是点击。
常用规则的举例如下:
比如行为埋点:{团队|业务|角色}_{组件|页面}_{具体元素}_{动作}
示例:
front_alarm_sw : front代表项目,alarm代表功能,sw是展示,ck是点击
front_alarm1_detail_table_point_ck :front代表项目,alarm1_detail代表功能,table组件,point小圆点组件,ck点击
埋点流程规范
如果你发现每天有大量埋点错误反馈,并导致很多错误的分析结论,一个错误的分析结果还不如没有数据分析结果。造成这个问题的原因包括:
- 前端埋点涉及复杂的交互,难以找准埋点位置;
- 埋点的验收流程不完善,没有经过测试和产品经理的测试和验收,验证不完备;
好的埋点需求应该和业务功能需求同等重要,也需要经历软件开发的整个生命周期,如果能严格按照一个规范的流程处理埋点,以上问题会得到更好的解决。
规范内容
需求阶段:
确定埋点信息,核心包括五方面信息:事件ID、埋点名称、埋点描述、埋点属性以及截图。
如何落地:
如果不按照规则和流程埋点将不会上报相关数据,制定强制规定。
开发什么功能:
埋点全文检索能力、自动找到重复埋点(语义相近或者数据相近)功能。
开发阶段:
务必和开发沟通,并让开发在完全理解业务语义的情况下,在前端按照埋点代码规范进行埋点。
如何落地:
静态代码检查。
开发什么功能:
开发探测每个埋点对应到的代码文件和代码行,开发根据人均事件量级进行监控报警功能。
测试阶段:
务必和测试沟通,并让测试在完全理解业务语义的情况下,通过CodeReview和埋点测试两种方式对埋点正确性进行验证。
如何落地:
规定如果未经测试的埋点不允许上报埋点数据。
开发什么功能:
提供所见即所得的埋点测试平台。
验收阶段:
确保相关人员在完全理解业务语义的情况下,可以通过与自比较和他比较的方式来进行验证。
举例:
- 他比较验证:前端某业务点数量和对应服务端数据应该基本相当。
如何落地:
规定如果未经验证的埋点不允许上报埋点数据。
开发什么功能:
提供埋点实时数据查询。
清理阶段:
确认完全理解语义的情况下,可对业务发生巨大变化或者不在维护的埋点进行废弃。
如何落地:
3个月以上未被使用的埋点、1个月以上数据为0的埋点自动废弃。3个月后使用次日会自动开启采集。
开发什么功能:
根据规则提供针对未使用埋点的计算、并自动废弃。
可以看出,规范要落地,需要整个公司的共识,也需要从上而下的压力,还有强势的制度。比如针对全公司个部门做评分,评分规则基于埋点和数据分析抽象出来。
另外我们在前端埋点中也遇到过一些注意事项,整理如下,希望对大家有所帮助。
注意事项:
一些埋点安全性问题:
如果你使用普通的http 协议,在数据传输的过程存在被劫持(包括不限于:JS代码注入等)的可能性,造成H5页面中出现诸如:未知的广告或者原网页被重定向等问题。为了降低此类事件发生的可能性,建议最好使用https 协议(倡导全站https),以确保数据传输过程的完整性,安全性。
版本迭代的时候埋点需要注意什么?
- 如果是公用模块,可以非常放心安全的全量迁移埋点;
- 如果是新增模块,那就需要注意是否遵循了最新的埋点规范,有没有重复的埋点命名存在,埋点是否符合业务逻辑;
- 如果是下线模块,那就需要评估下线后对数据的影响范围,而且要第一时间充分周知相关方,让各方参与评估;
- 如果是更新模块,需要评估在原有埋点上需要修改的埋点内容,是否需要重新埋点,删除不需要的埋点,而且要修改功能的数据承接。





")
")





/title.png)
/a.png "from https://juejin.im/post/5a062fb551882535cd4a4ce3")
/5LbsY.jpg "图1")
/nTmNe.jpg "图2")
/lQQX7.png)








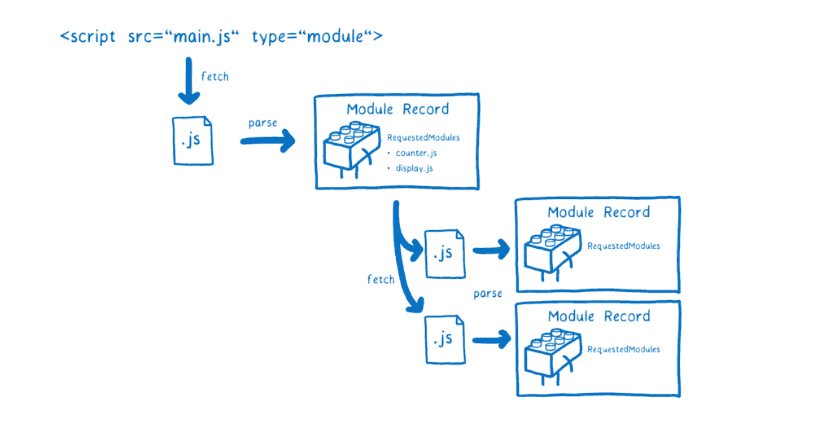
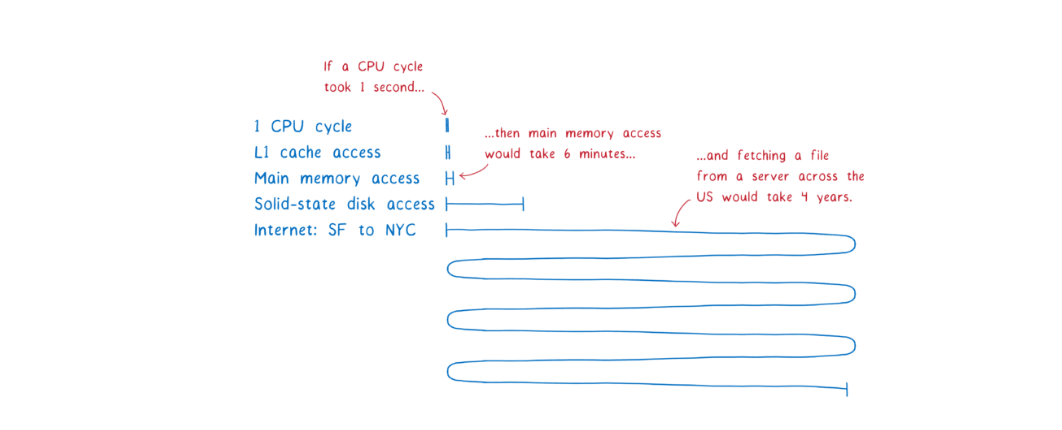
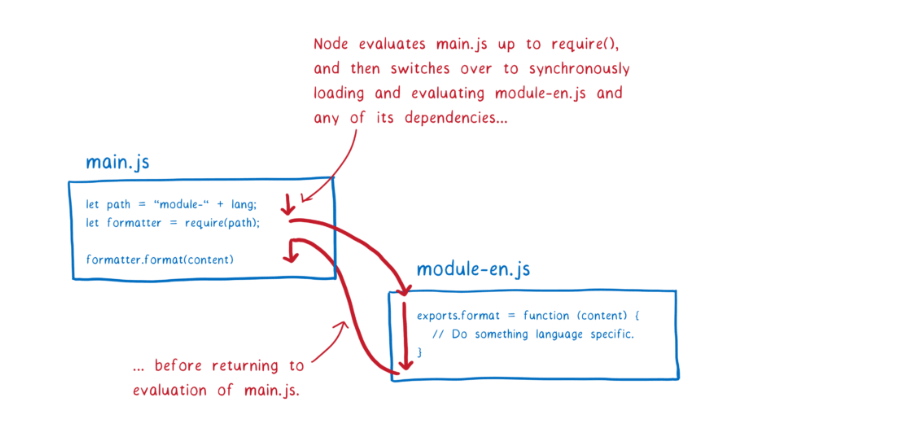

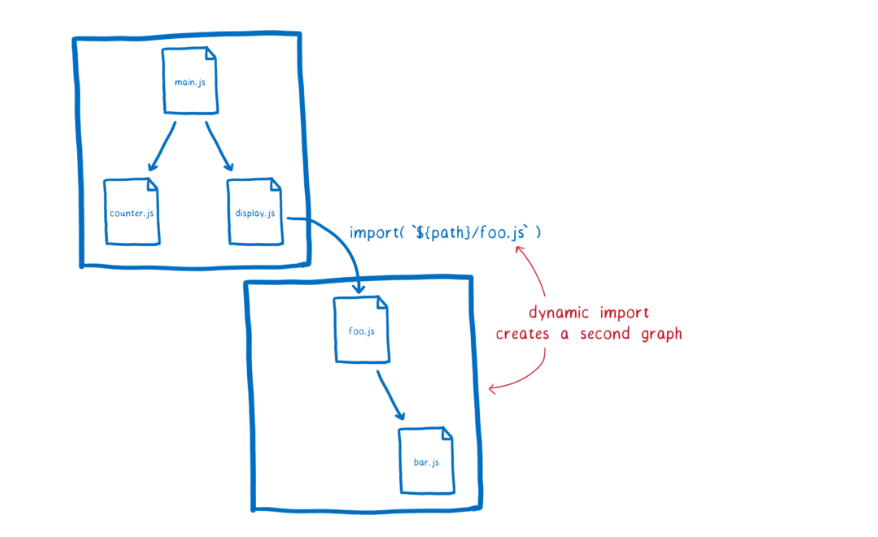




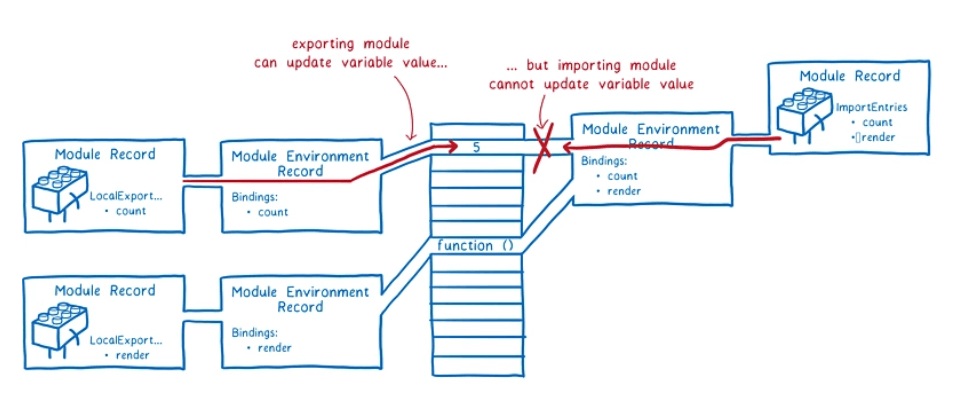

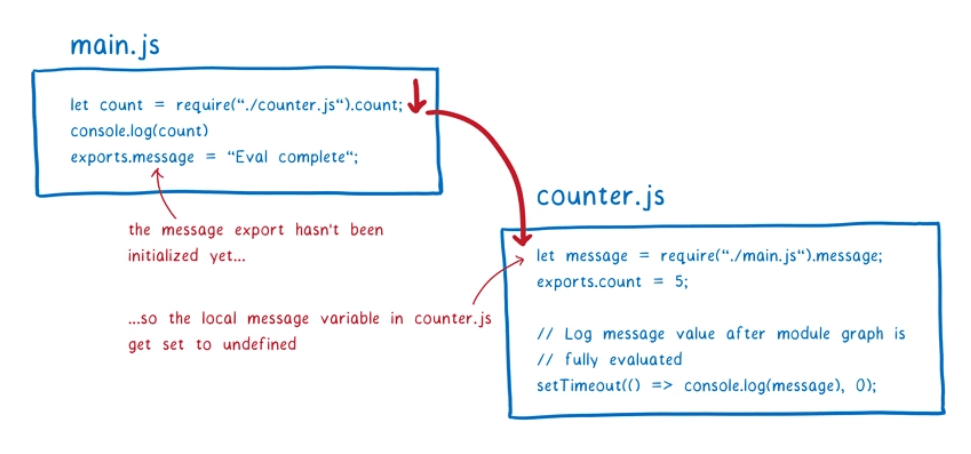
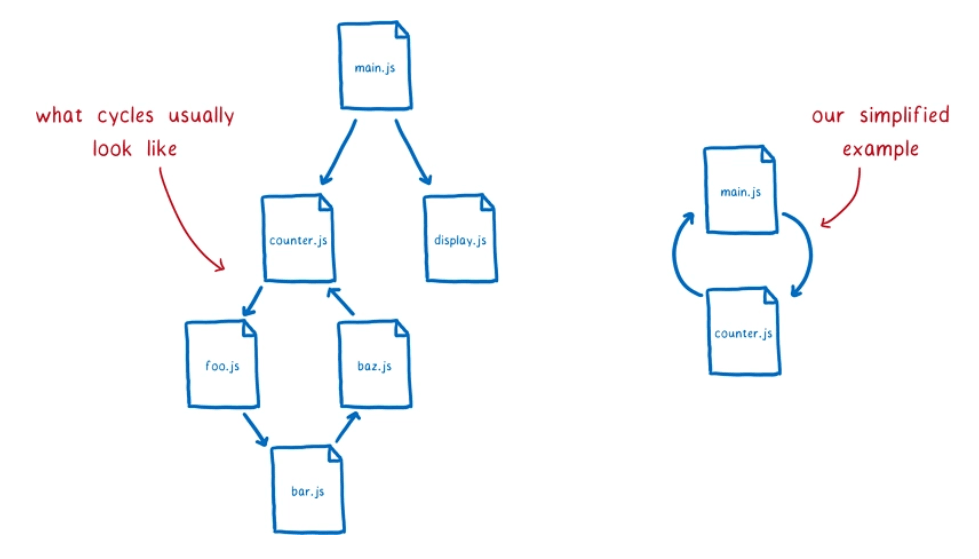

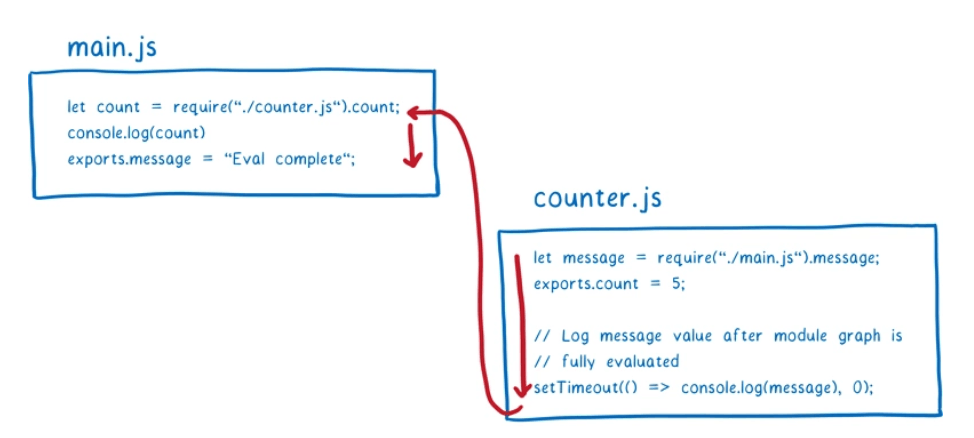


 图片来源:
图片来源: