最近报了一个课程-告别低效,人人必备的聪明工作法,少数派出品。
其实很早以前就接触了相关的内容,还买了几本书,买了几个工具,其中有本书对我还是比较有用的,这本书更多强调的是工具,是术的方面,让我学会了用工具做时间管理。比如番茄钟、滴答清单等。
之所以再报这门课程是为因为,之前的时间管理训练做的不是很好,没有坚持下来,国外传来的四象限法、GTD、SMART、精力管理…这些很多地方出现的词语,主要还是讲思路方面的问题,对于我来说现在可能能真正落地的更合适,而这门课程里面的某些内容就是我需要的,同时想要通过这门课程让自己能更加重视提升工作效率的重要性,能提升一点也是好的。
文件管理
这个应该是我做的最差的,文件都是摆满桌面,一通找,不过后来我找到了两个工具,超级超级超级好用,Everything+Wox 这两个东西真的是帮了我的大忙,让我不至于老是风中凌乱。我是觉得这两个就已经基本上解决了我的诉求,让我能快速的找到我的文件,不过稍有遗憾的是你的大概记得住你的文件名或者文件夹名才能有用,所以做好文件的管理是基础。课程中讲了一个工具Droplt,亲测好用,能根据我的规则帮我进行文件的分门别类。你也能设置自动分类。
高效获取信息
- 信息源的质量
- 信息源的半衰期(信息的有效时间)、信息源的稀缺程度(价值高低),通常是半衰期越长,稀缺程度越高。
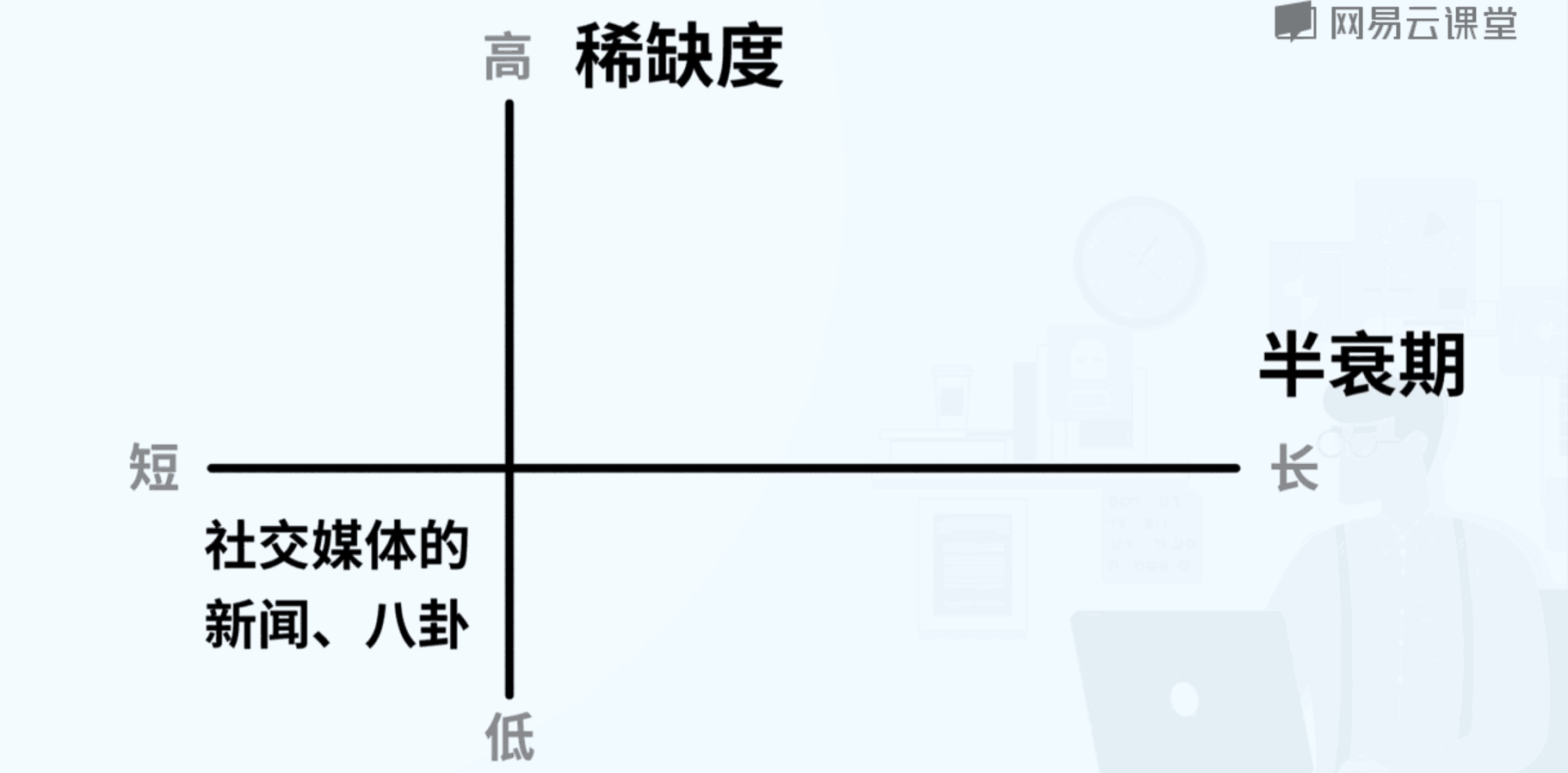
- 掌握信息获取的主动权
- 获取信息尽量是通过pull而不是push(推送,通常不是有价值的信息),pull就表示是自己主动去寻找的信息
- 避免回声效应,即老是停留在自己的认知层面,屏蔽了外面的信息。
浪起来的我-效率提升工具
我这儿就笼统的分享一下我为了提升效率而使用的一套工具,有些花钱有些用的免费的,这儿说的提升效率包括工作、学习、生活上的。
工作节奏:滴答清单付费版、ToDoist、番茄土豆
文件搜索:Everything、Wox
学习:记录、收藏:印象笔记付费版,Pocket(稍后阅读)
回顾:目标笔记
适合自己的才是最好的,你觉得用的爽然后确实有改善那就行了。
学习提升方法论
在学习记忆中始终保持必要难度是必要的,这样才能训练自己的记忆能力。
提升知识记忆的内化效果方法
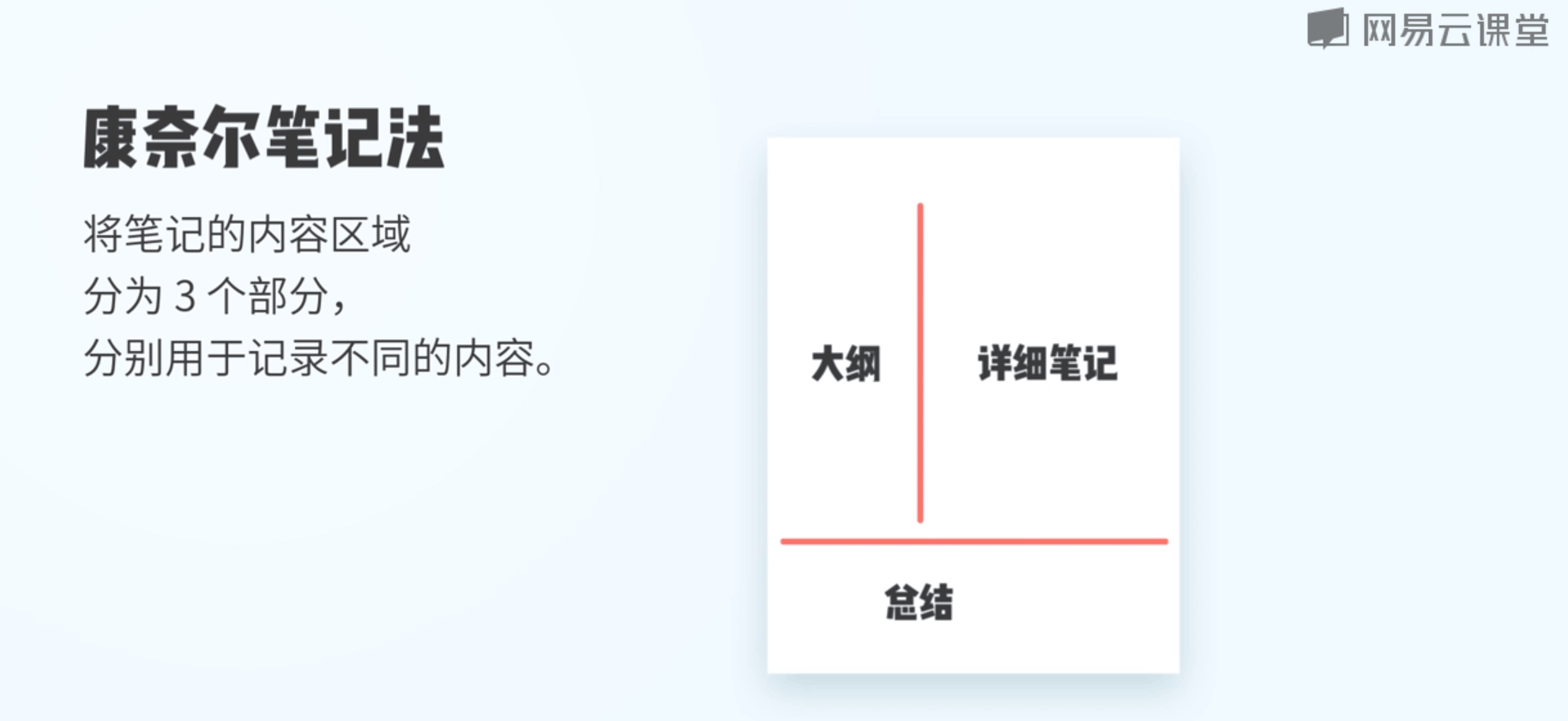
1.复述意识=>复述学习的内容,比如用康奈尔笔记法做知识回顾
2.间隔学习,知识交叉,不能长时间一直学习某个知识,因为这样就没有保证记忆的难度。
3.费曼学习法=>把学到的知识讲给非专业人士听,用于检测自身是否对知识理解不到位,然后再反过头来深化
记忆方法-记忆宫殿
即把需要记忆的内容,抽象成图画,最终转化为情景式的关联记忆,因为人的空间记忆能力是超强的,所以用大脑的这块区域来记忆,坚持训练,肯定对记忆力有提升。我小试了几天,发现通过想象画面来记忆真的比死记硬背更有效且更有劲。
课程还提到了一个工具:anki,加强记忆力的工具。

实操
邮件FAST法则

邮件ABC法则

- 思维导图做会议记录
名词解释
任务管理LTF体系:List(列表,行动项) Tag(标签,标识) Filter(过滤器,搜索)
邮件FAST法则:Fliter(过滤) Archive(归档) Transfer(流转) Snooze(延后)



