梦想金山-优秀的程序员
优秀程序员四大修为
1.坚韧不拔
2.知识全面
3.完美主义
4.团结协作
优秀程序员四大修为
1.坚韧不拔
2.知识全面
3.完美主义
4.团结协作
在学习浏览器那块,有一块时关于渲染的。
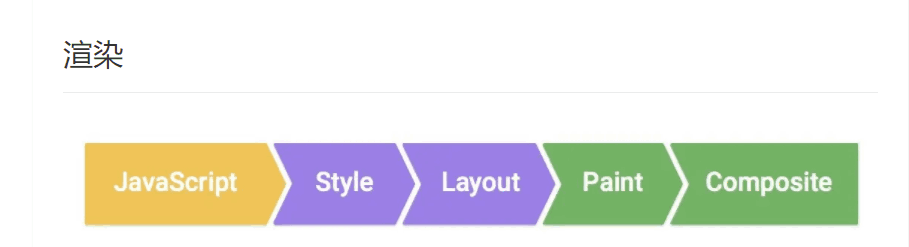
在此过程中发现了一个网站 CSS Triggers,说明哪些css可以触发浏览器的重新渲染(layout、Paint、Composite),所以这个网站是用来告诉开发者不同内核浏览器对css属性修改的重绘/回流情况,开发者知道了这些细节可以提高页面性能。
小而美的网站,感谢这两位大佬 Paul and Surma。
我在此简单做个记录,方便后续的使用。
如图所示,点击每个属性会有详细的说明。
google的十大真理
金山-梦想与野心。
金山区别于其它中关村企业最核心的地方,金山是一家有野心的公司。
求伯君自己成功的经验三点:

首先解释一下啊 ,这儿的猫头鹰表示,晚睡晚起一族,当然我就是晚睡晚起一族,那为什么我还要说我希望呢,因为我想实现的是文章中对猫头鹰的定义,很显然我还没达到那种境界,所以是希望。
文章中的这句话是需要划重点的。这就是我的目标,哈哈哈哈…虽然俗语说”早睡早起,健康、聪明又富有”,但有一项研究表明,”猫头鹰”跟”百灵鸟”一样健康,一样聪明,甚至更加富有。
其实从文章中我们可以提取到几点信息。
百灵鸟
表面解释:早睡早起,深度解释请看文章。
猫头鹰
表面解释:晚睡晚起,深度解释请看文章。
作为NPMD的厂商

最近生育基金的事闹得沸沸扬扬,更有甚者,江苏的《新华日报》携手,南京大学长江产业经济研究院 刘志彪、张 晔两位砖家,发表了不但应该缴生育基金还他么说了不生就只要老了才能取。
我就想说,这两位究竟平时吃什么,大脑那么奔放。我觉得马光远先生评论改事件的时候有句话很到位,“老百姓不是负责交税和交配的”
基本的问题是什么,自己心里没点数么?光让生不用养吗?养得起吗?养得好吗?能养活吗?
…….
一大堆根本上的问题不出方案,这种拍马屁不要脸的舔着上。
刚好这段时间对接其他产品,刚好处理了一下跨域的问题,借此机会稍微更加了解一下跨域(Cross-origin resource sharing)。
搬运搬运…
同源策略是一种Web浏览器安全性机制,旨在防止网站相互攻击。
同源策略限制一个源上的脚本访问另一源的数据。源由URI方案,域和端口号组成。
同源策略是一种限制性的跨域规范,它限制了网站与源域外部资源进行交互的能力。起源于多年前的策略是针对潜在的恶意跨域交互(例如,一个网站从另一个网站窃取私人数据)做出的响应。通常,它允许一个域向其他域发出请求,但不允许访问响应。
同源策略它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSFR等攻击。所谓同源是指”协议+域名+端口”三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
同源策略限制以下几种行为:
1 | 1.) Cookie、LocalStorage、IndexedDB 等存储 |
但是有三个标签是允许跨域加载资源:
1 | <img src=XXX> |
1 | URL 说明 是否允许通信 |
1、 通过jsonp跨域
2、 iframe跨域
5、 postMessage跨域
6、 跨域资源共享(CORS)
7、 nginx代理跨域
8、 nodejs中间件代理跨域
9、 WebSocket协议跨域
比较抱歉的是我只用过nginx代理跨域、跨域资源共享(CORS)、WebSocket协议跨域…。
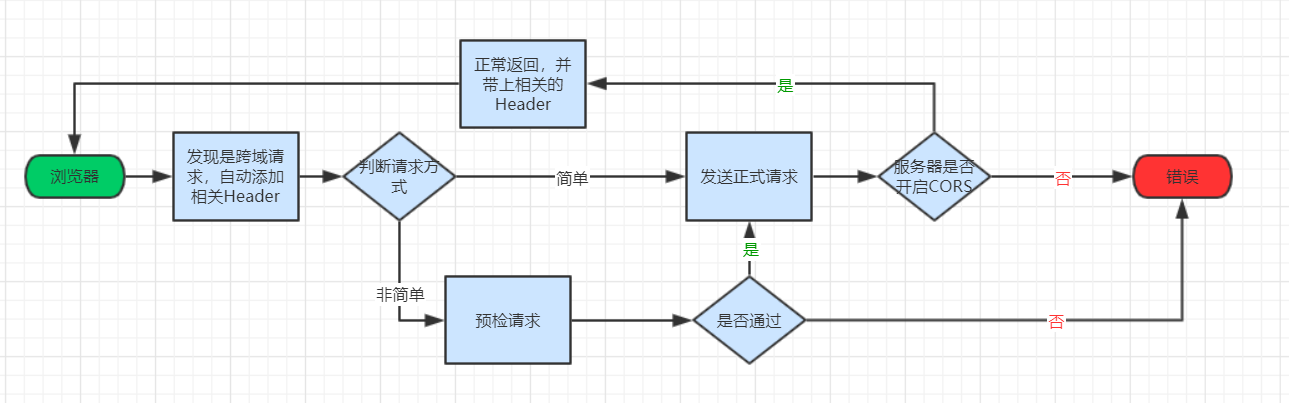
在大多数情况下,在用户浏览器中运行的脚本仅需要访问源相同的资源(请考虑首先对服务JavaScript代码的同一后端进行API调用)。因此,JavaScript通常无法访问其他来源的资源,这对安全性而言是一件好事。但是有些情况下需要跨域请求的。例如,不同系统间的一些对接。解决该问题就需要实现CORS,跨域资源共享(CORS)是一种浏览器机制,可实现对位于给定域外部的资源的受控访问。
如果不需要cookie的话,整个CORS通信过程都是浏览器自动完成的,前端不需要做额外的编码。浏览器一旦发现请求跨源,就会自动添加一些附加的头信息,复杂请求还会多一次预检的请求,但我们是不用感知的。因此,实现CORS通信的关键是服务器开启CORS。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。