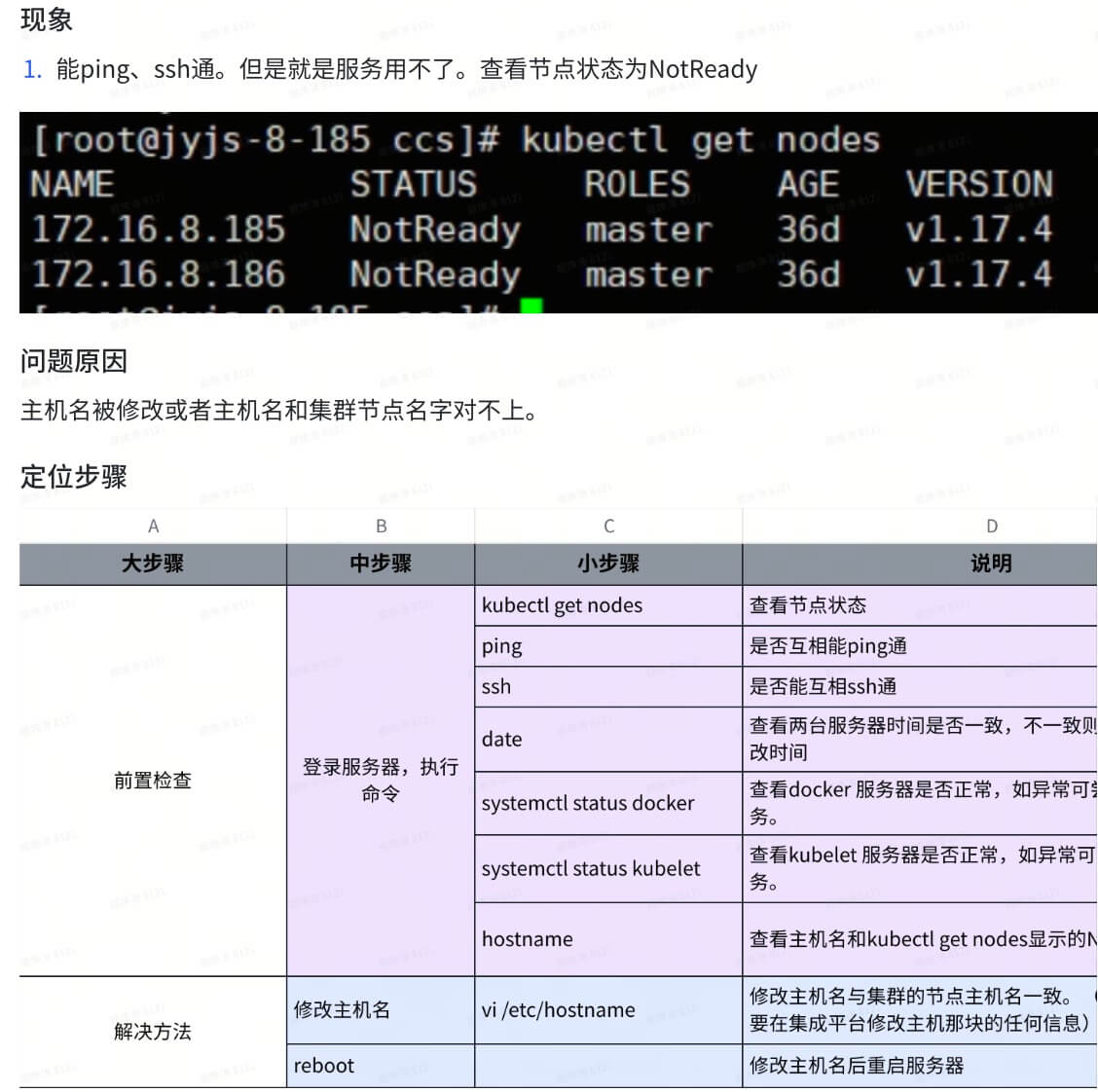
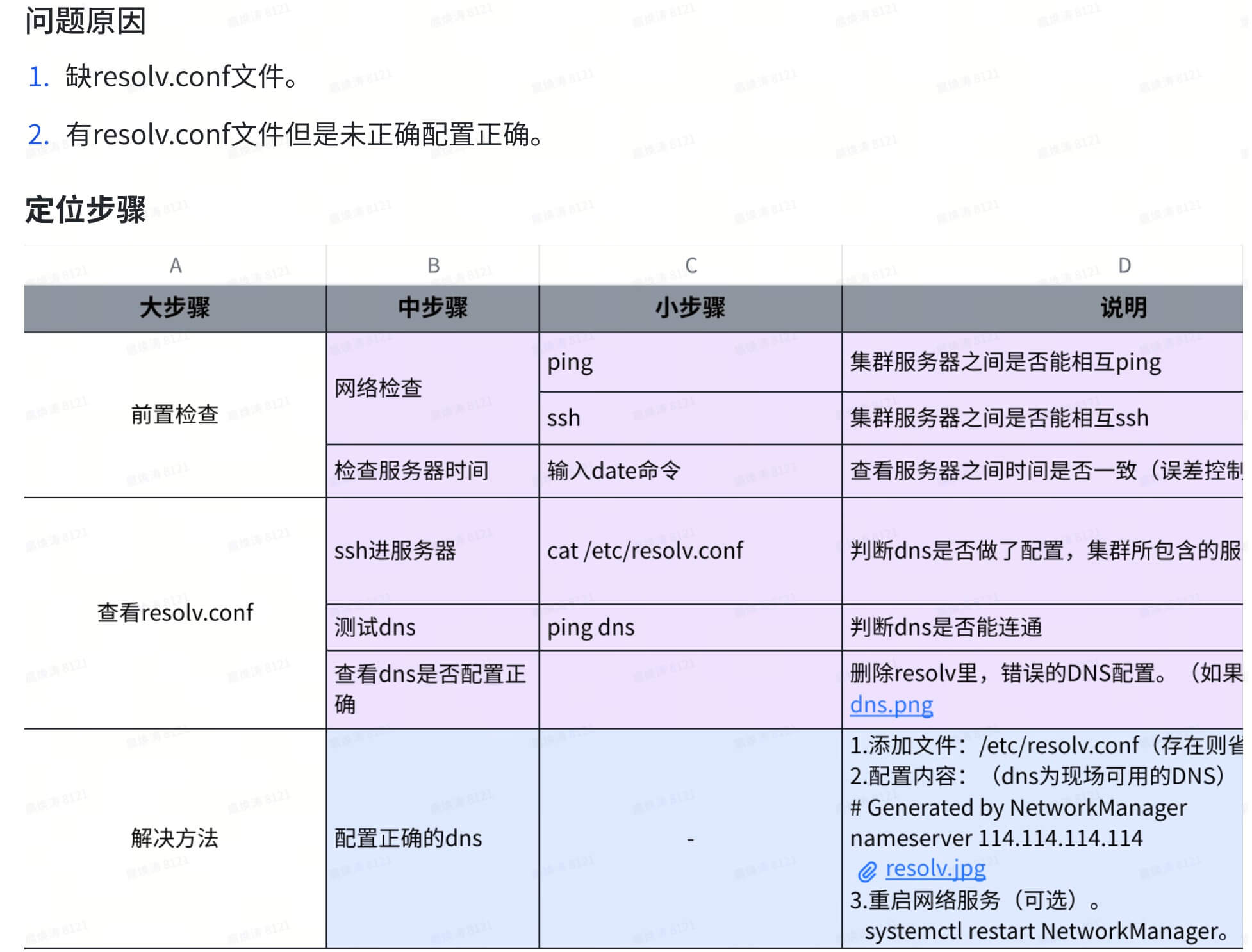
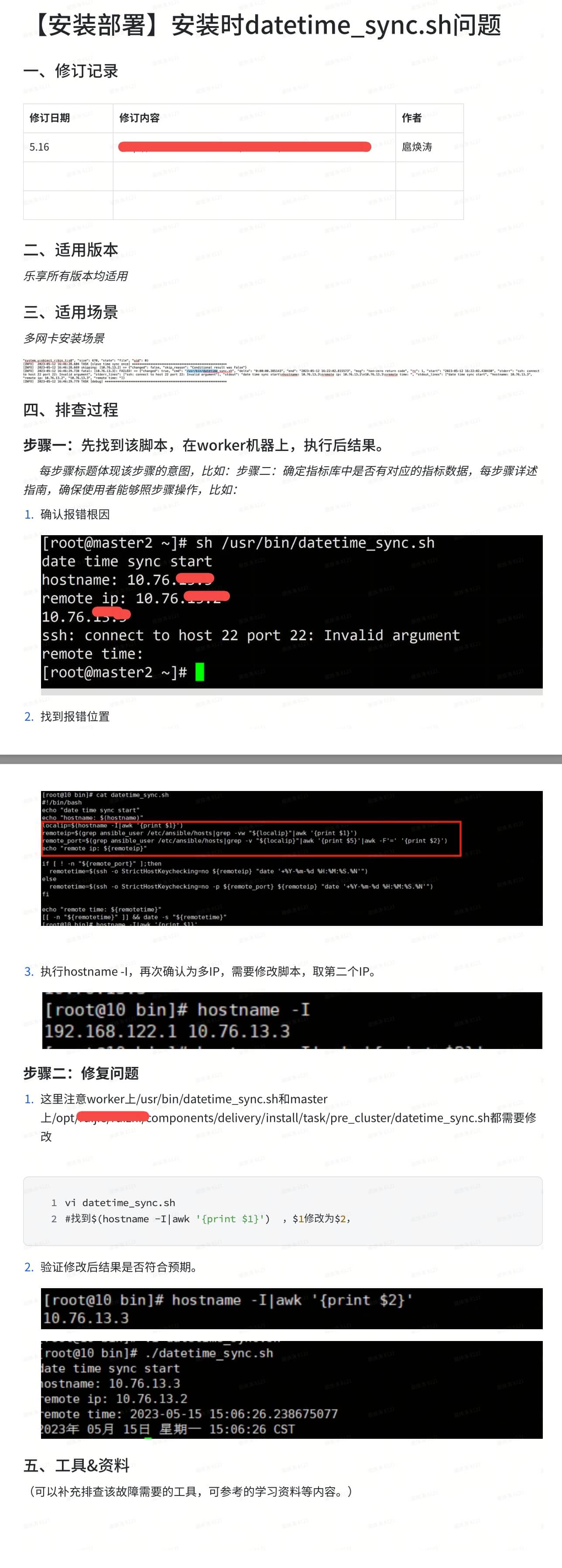
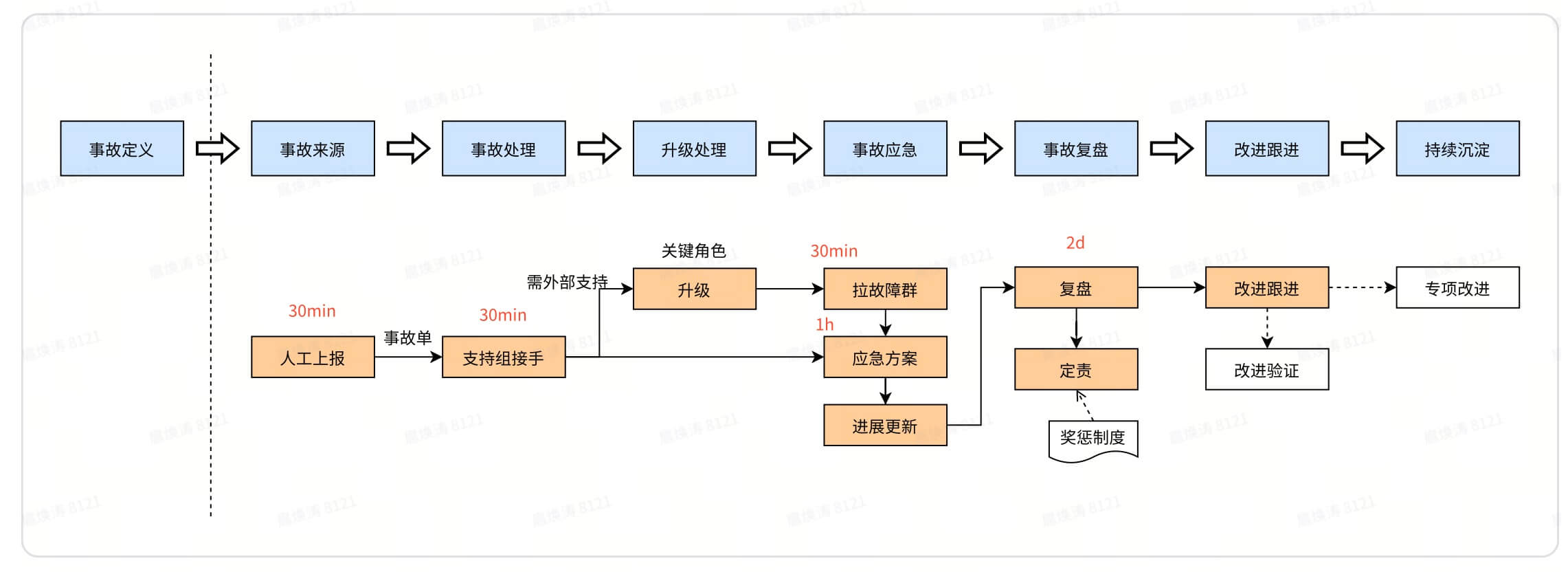
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
|
// 任务优先级定义
private enum TaskPriority {
HIGH(0),
MEDIUM(5),
LOW(10);
private final int value;
TaskPriority(int value) {
this.value = value;
}
public int getValue() {
return value;
}
}
/**
* manage-biz Powerjob 调度类
* 优化版本 - 任务削峰与队列管理
*
* @author hht
* @since 2024-09-10
*/
@Component(value = "manageBizPowerjobDispatcher")
@Slf4j
@RequiredArgsConstructor
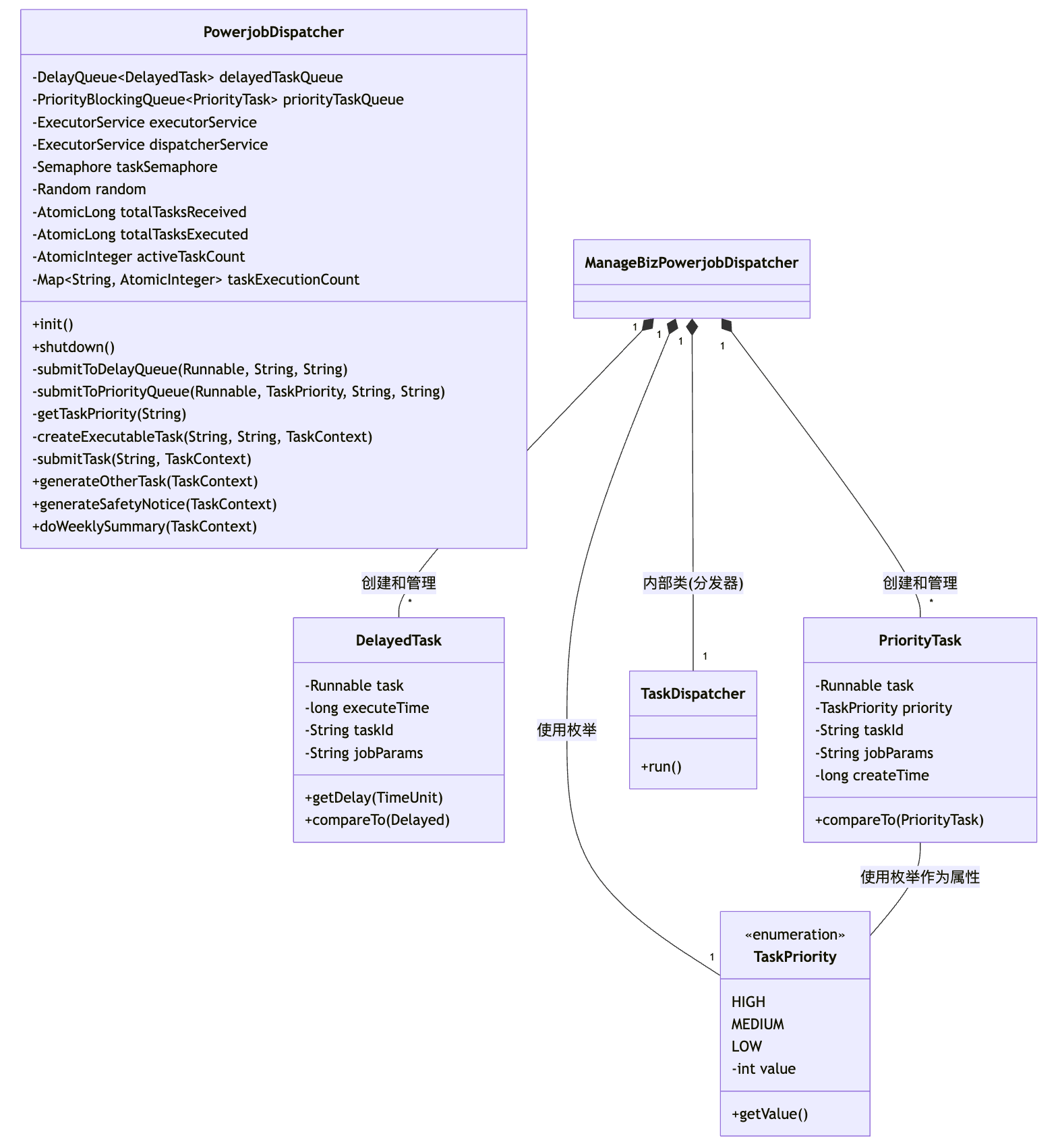
public class ManageBizPowerjobDispatcher {
private final IXxxScheduleService XxxScheduleService;
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
/** 平安通告powerjob任务id */
public static final String TASK_SAFETY_NOTICE_ID = "generateXxx";
public static final String SUCCESS = "success";
// 配置参数,可从配置文件注入
@Value("${powerjob.task.max-concurrent:10}")
private int maxConcurrentTasks;
@Value("${powerjob.task.queue-capacity:500}")
private int queueCapacity;
@Value("${powerjob.task.max-delay-minutes:5}")
private int maxDelayMinutes;
@Value("${powerjob.task.worker-threads:20}")
private int workerThreads;
// 延迟任务定义
@Data
private static class DelayedTask implements Delayed {
private final Runnable task;
private final long executeTime;
private final String taskId;
private final String jobParams;
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(executeTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
}
// 优先级任务定义
@Data
private static class PriorityTask implements Comparable<PriorityTask> {
private final Runnable task;
private final TaskPriority priority;
private final String taskId;
private final String jobParams;
private final long createTime;
@Override
public int compareTo(PriorityTask other) {
// 先按优先级排序,再按创建时间排序
int priorityCompare = Integer.compare(priority.getValue(), other.priority.getValue());
if (priorityCompare != 0) {
return priorityCompare;
}
return Long.compare(createTime, other.createTime);
}
}
/**
* 1.单独的线程,负责从队列中获取任务并分发
* 2.协调延迟队列和优先级队列
* 3.控制任务的并发执行数量
*/
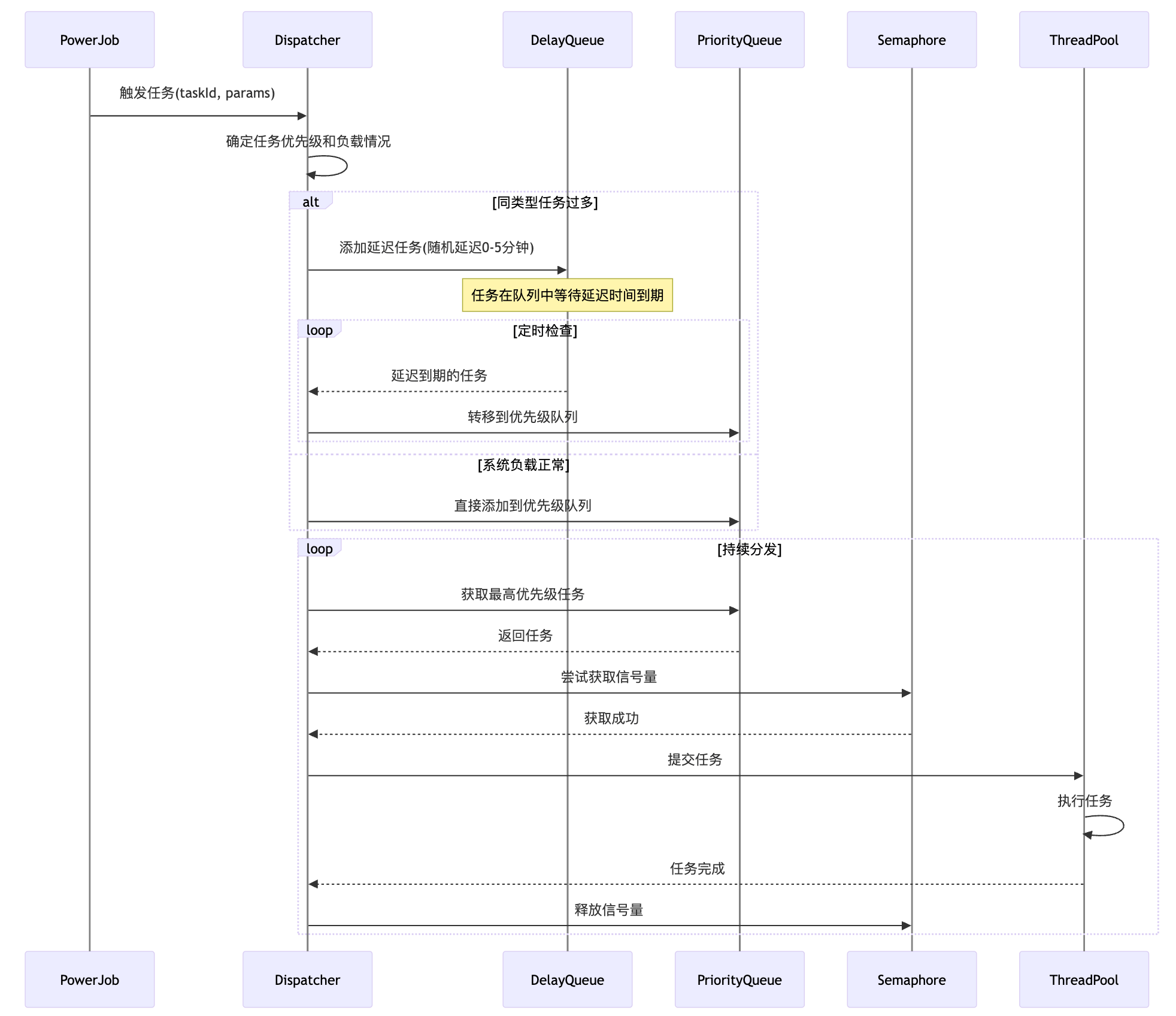
private class TaskDispatcher implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
// 先检查延迟队列
DelayedTask delayedTask = delayedTaskQueue.poll();
if (delayedTask != null) {
// 将任务添加到优先级队列
submitToPriorityQueue(delayedTask.getTask(), TaskPriority.HIGH, delayedTask.getTaskId(), delayedTask.getJobParams());
continue;
}
// 从优先级队列取任务执行
PriorityTask priorityTask = priorityTaskQueue.take();
if (priorityTask != null) {
try {
// 获取信号量,控制并发
taskSemaphore.acquire();
// 记录任务开始执行
activeTaskCount.incrementAndGet();
taskExecutionCount.computeIfAbsent(priorityTask.getTaskId(), k -> new AtomicInteger(0)).incrementAndGet();
// 提交到线程池执行
executorService.submit(() -> {
try {
log.info("执行任务: {}, 参数: {}", priorityTask.getTaskId(), priorityTask.getJobParams());
priorityTask.getTask().run();
} catch (Exception e) {
log.error("任务执行异常: {}", priorityTask.getTaskId(), e);
} finally {
// 释放信号量
taskSemaphore.release();
// 更新计数器
activeTaskCount.decrementAndGet();
AtomicInteger counter = taskExecutionCount.get(priorityTask.getTaskId());
if (counter != null) {
counter.decrementAndGet();
}
}
});
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} catch (Exception e) {
log.error("任务分发器异常", e);
}
}
}
}
// 任务队列和执行器
private DelayQueue<DelayedTask> delayedTaskQueue;
private PriorityBlockingQueue<PriorityTask> priorityTaskQueue;
private ExecutorService executorService;
private ExecutorService dispatcherService;
private Semaphore taskSemaphore;
private Random random;
// 任务执行状态监控
private AtomicLong totalTasksReceived = new AtomicLong(0);
private AtomicLong totalTasksExecuted = new AtomicLong(0);
private AtomicInteger activeTaskCount = new AtomicInteger(0);
private Map<String, AtomicInteger> taskExecutionCount = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
// 初始化任务队列
delayedTaskQueue = new DelayQueue<>();
priorityTaskQueue = new PriorityBlockingQueue<>(queueCapacity);
// 初始化线程池
executorService = Executors.newFixedThreadPool(workerThreads, new ThreadFactory() {
private final AtomicInteger counter = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "task-worker-" + counter.getAndIncrement());
thread.setDaemon(true);
return thread;
}
});
// 初始化分发器线程,
dispatcherService = Executors.newSingleThreadExecutor(r -> {
Thread thread = new Thread(r, "task-dispatcher");
thread.setDaemon(true);
return thread;
});
// 初始化信号量
taskSemaphore = new Semaphore(maxConcurrentTasks);
// 初始化随机数生成器
random = new Random();
// 启动任务分发线程
dispatcherService.submit(new TaskDispatcher());
log.info("任务调度器初始化完成,最大并发任务数: {}, 队列容量: {}, 最大延迟分钟数: {}, 工作线程数: {}",
maxConcurrentTasks, queueCapacity, maxDelayMinutes, workerThreads);
}
@PreDestroy
public void shutdown() {
// 关闭调度器
if (dispatcherService != null) {
dispatcherService.shutdownNow();
}
// 关闭执行器
if (executorService != null) {
executorService.shutdown();
try {
if (!executorService.awaitTermination(30, TimeUnit.SECONDS)) {
executorService.shutdownNow();
}
} catch (InterruptedException e) {
executorService.shutdownNow();
Thread.currentThread().interrupt();
}
}
log.info("任务调度器已关闭,总接收任务数: {}, 总执行任务数: {}",
totalTasksReceived.get(), totalTasksExecuted.get());
}
/**
* 提交任务到延迟队列
*/
private void submitToDelayQueue(Runnable task, String taskId, String jobParams) {
// 随机延迟时间,在0到maxDelayMinutes分钟之间
long delayMs = random.nextInt((int) TimeUnit.MINUTES.toMillis(maxDelayMinutes));
DelayedTask delayedTask = new DelayedTask(task, delayMs, taskId, jobParams);
delayedTaskQueue.offer(delayedTask);
totalTasksReceived.incrementAndGet();
log.info("任务已提交到延迟队列: {}, 延迟: {}ms", taskId, delayMs);
}
/**
* 提交任务到优先级队列
*/
private void submitToPriorityQueue(Runnable task, TaskPriority priority, String taskId, String jobParams) {
PriorityTask priorityTask = new PriorityTask(task, priority, taskId, jobParams);
priorityTaskQueue.offer(priorityTask);
log.info("任务已提交到优先级队列: {}, 优先级: {}", taskId, priority);
}
/**
* 获取任务类型对应的优先级
*/
private TaskPriority getTaskPriority(String taskId) {
switch (taskId) {
case TASK_SAFETY_NOTICE_ID:
case TASK_PUSH_SERVICE_STATUS_ID:
return TaskPriority.HIGH;
case TASK_TENANT_SERVICE_PHASE_ID:
case TASK_WEEKLY_SUMMARY:
return TaskPriority.MEDIUM;
default:
return TaskPriority.LOW;
}
}
/**
* 创建可执行的任务
*/
private Runnable createExecutableTask(String taskId, String jobParams, TaskContext taskContext) {
switch (taskId) {
case TASK_SAFETY_NOTICE_ID:
return () -> generateXxxTask(taskContext);
case TASK_OTHER:
return () -> generateOtherTask(taskContext);
...
default:
throw new IllegalArgumentException("未知的任务类型: " + taskId);
}
}
/**
* 通用任务提交方法
*/
private ProcessResult submitTask(String taskId, TaskContext taskContext) {
try {
totalTasksReceived.incrementAndGet();
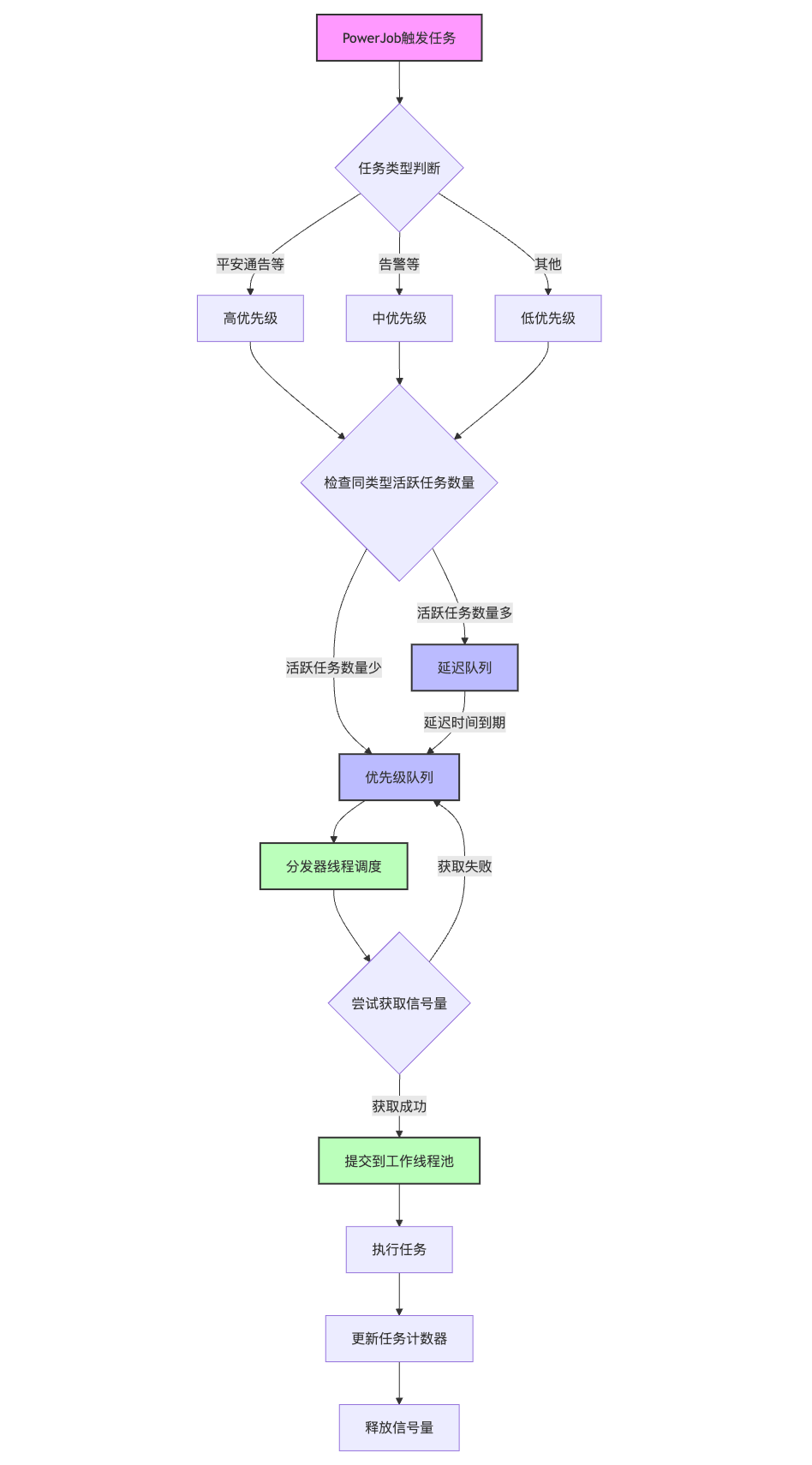
// 检查任务执行情况,如果已有大量相同类型任务,加入延迟队列
int activeCount = taskExecutionCount.computeIfAbsent(taskId, k -> new AtomicInteger(0)).get();
if (activeCount > maxConcurrentTasks / 2) {
log.warn("当前任务类型 {} 正在执行的数量较多: {}, 将使用延迟队列分散负载", taskId, activeCount);
submitToDelayQueue(createExecutableTask(taskId, taskContext.getJobParams(), taskContext), taskId, taskContext.getJobParams());
} else {
// 根据任务类型分配优先级
TaskPriority priority = getTaskPriority(taskId);
submitToPriorityQueue(createExecutableTask(taskId, taskContext.getJobParams(), taskContext), priority, taskId, taskContext.getJobParams());
}
return new ProcessResult(true, formatResponse(SUCCESS, taskId));
} catch (Exception e) {
log.error("提交任务异常: {}", taskId, e);
return new ProcessResult(false, formatResponse(e.getMessage(), taskId));
}
}
// ====== 以下是原始的PowerJob任务处理方法,改为使用队列系统 ======
/**
* 告警任务
*/
@PowerJobHandler(name = TASK_OTHER)
public ProcessResult generateOtherTask(TaskContext taskContext) {
log.info("==================== 调度触发(其它任务) ======================");
return submitTask(TASK_OTHER, taskContext);
}
private ProcessResult generateOtherTask(TaskContext taskContext) {
try {
StrategyJobParams jobParams = new StrategyJobParams();
if (StringUtils.hasLength(taskContext.getJobParams())) {
jobParams = OBJECT_MAPPER.readValue(taskContext.getJobParams(), StrategyJobParams.class);
}
strategyScheduleService.generateTask(jobParams);
totalTasksExecuted.incrementAndGet();
return new ProcessResult(true, formatResponse(SUCCESS, TASK_OTHER));
} catch (Exception e) {
log.error("调度执行【其它任务】异常", e);
return new ProcessResult(false, formatResponse(e.getMessage(), TASK_OTHER));
}
}
/**
* 生成平安通告
*/
@PowerJobHandler(name = TASK_SAFETY_NOTICE_ID)
public ProcessResult generateXxx(TaskContext taskContext) {
log.info("==================== 调度触发(平安通告) ======================");
return submitTask(TASK_SAFETY_NOTICE_ID, taskContext);
}
private ProcessResult generateXxxTask(TaskContext taskContext) {
try {
// 获取调度任务的参数
StrategyJobParams jobParams = null;
if (StringUtils.hasLength(taskContext.getJobParams())) {
jobParams = OBJECT_MAPPER.readValue(taskContext.getJobParams(), StrategyJobParams.class);
}
// 生成平安通告
XxxScheduleService.autoGenerateBatch(jobParams);
totalTasksExecuted.incrementAndGet();
return new ProcessResult(true, formatResponse("success", TASK_SAFETY_NOTICE_ID));
} catch (Exception e) {
log.error("调度执行【平安通告】异常", e);
return new ProcessResult(false, formatResponse(e.getMessage(), TASK_SAFETY_NOTICE_ID));
}
}
private String formatResponse(String info, String id) {
return String.format("{\"taskId\": \"%s\", \"info\": \"%s\"}", id, info);
}
}
|