0%
怎么写高效的css
https://thenextweb.com/news/writing-efficient-css-understand-your-selectors
https://programmerinnervoice.wordpress.com/2013/12/18/how-does-browser-read-css-selector/
https://stackoverflow.com/questions/5797014/why-do-browsers-match-css-selectors-from-right-to-leftt
Don’t Use Inline-Styles
Avoid the !important tag
https://www.freecodecamp.org/news/7-important-tips-for-writing-better-css/
https://csswizardry.com/2011/09/writing-efficient-css-selectors/
ES2020/2021
背景
今天看阮老师的科技周刊的时候,里头提到了ES2021(作者默认所有的提案最终都会被通过),正好借此梳理一下,ES2020和ES2021,个人使用过的以及后续可能会使用的一些功能,所以这篇不是科普类型,纯属个人喜好的记录。
开始
空值合并运算符:??
**??**是一个逻辑操作符,当左侧的操作数为
null或者undefined时,则返回右侧操作数,否则返回左侧操作数。所以该运算符完美适配默认值的场景。
1 | const foo = null ?? 'default string'; |
多说一句:
设置默认值以前常用的是:**||**(逻辑或操作符),但是都知道不用用它作为有false和0的情况(因为||**判断时,会把值转换为布尔值,而false和0转为布尔值时都是false,所以对于数字类型和布尔类型的用||设置默认值是不合理的+)
可选的链接运算符:?.
嵌套对象时特别好用。表达式还短。
如果引用为空(null 或 undefined),则表达式会短路返回 undefined。
1 |
|
Promise.any() and AggregateError
Promise.any()方法接受一组 Promise 实例作为参数,包装成一个新的 Promise 实例。只要参数实例有一个变成fulfilled状态,包装实例就会变成fulfilled状态;如果所有参数实例都变成rejected状态,包装实例就会变成rejected状态
阮一峰 ECMAScript 6 (ES6) 标准入门教程 第三版
Promise.any()跟Promise.race()方法很像,只有一点不同,就是不会因为某个 Promise 变成rejected状态而结束。
1 | Promise.race([ |
globalThis
全局属性 globalThis 包含全局的 this 值,类似于全局对象(global object)。globalThis 提供了一个标准的方式来获取不同环境下的全局 this 对象(也就是全局对象自身)不用在考虑不同的环境获取方式不一样的问题。
String replaceAll()
1 | const newStr = str.replaceAll(regexp|substr, newSubstr|function). |
replaceAll(pattern,replacement) 方法返回一个新字符串,新字符串所有满足 pattern 的部分都已被replacement 替换。pattern可以是一个字符串或一个 RegExp, replacement可以是一个字符串或一个在每次匹配被调用的函数。
old:
1 | const str = "zhangsan is wangmazi's 舅子,wangmazi is zhangsan's 妹夫"; |
new:
1 | const str = "zhangsan is wangmazi's 舅子,wangmazi is zhangsan's 妹夫"; |
逻辑赋值运算符:(&&= ||= ??=)
1 | x ||= y; |
下划线作为数字分隔符
1 | const billion = 1000_000_000; |
Promise.allSettled
我通常在页面初始化需要多个数据且相互之间又没联系的时候会用它。
**Promise.allSettled()**方法接受一组Promise 实例作为参数,包装成一个新的 Promise 实例。只有等到所有这些参数实例都返回结果(不管是
fulfilled还是rejected),返回结果是一个对象数组,每个对象表示对应的promise结果。当有多个彼此不依赖的异步任务成功完成时,或者我们不关心异步操作的结果,只关心每个
promise的结果时,通常使用它。
1 | const p1 = new Promise((resolve, reject) => setTimeout(resolve, 1000,'failed')); |
相比之下,
Promise.all()更适合彼此相互依赖或者在其中任何一个reject时就需要立即结束的场景。即Promise.all()其实无法确定所有请求都结束。
参考资料:
https://github.com/tc39/ecma262/releases
https://backbencher.dev/javascript/es2021-new-features
https://tc39.es/ecma262/2021/#sec-web-scripting
https://www.telerik.com/blogs/learn-new-features-introduced-javascript-es2021
https://blog.fundebug.com/2019/08/28/javascript-nullish-coalescing/
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
You're worrying about the wrong thing if you're trying to learn it all
别想着记住所有东西
https://www.kevinpowell.co/article/youre-worrying-about-the-wrong-things/
https://www.youtube.com/watch?v=vP2MNhC_Igw
为了成为一名前端开发人员,我们需要学习一百万零一件事,似乎每 30 秒就有另一件新东西需要我们添加到我们的武器库中。
学习新事物可能很有趣,但是当我们需要学习的新事物清单似乎不断增加时,它可能会让人不知所措。
还有一个大问题。当我们离开学习所有这些新东西时,我们他妈的怎么能记住我们已经学过的所有东西?
我经常被问到,通过 DM 或来自追随者的电子邮件,或者有时作为 YouTube 评论,询问记住所有内容的最佳策略。
事实是,我什么都不记得。我记得一些东西是因为我一直在使用它们,并且因为我主要关注 CSS。我使用它们的次数越多,与它们相处得越好,与它们相处的乐趣也就越多。但我不记得一切。
事实上,它甚至不接近。
这都是一个大谎言
当您观看我的 YouTube 视频或其他人编写代码时,似乎我无所不知。然后下周我发布了一个关于新主题的新视频,我也知道!
我当然是了!我已经把它写好了,而且我之前已经建立了那个东西。
大多数情况下,有关编码的视频和课程中的人们只是从其他屏幕上的已完成版本中复制代码。
事情需要计划好!否则,课程的质量将很糟糕。
但它确实给人一种错误的感觉,即那里的“专业人士”知道并记住一切。
没有人记得这一切
我喜欢听关于开发的播客的原因之一是当你仰望的人谈论他们是如何忘记事情的时候,或者不得不查找事情的时候(有时是我非常了解的事情!)。
不断在ShopTalk Show 上,他们的名字出现了,我非常尊重,他们谈论他们如何必须为他们写的一本书研究某些东西,然后发现自己不得不阅读他们自己书中的部分内容记住它是如何工作的。
我可以理解这一点,我确实看过我自己视频的一部分来记住如何做某些事情。
我知道这是我以前知道的东西(毕竟我确实制作了一个视频!),但是因为我有一段时间没有使用那个东西了,也许即使我制作了那个视频,我也不记得到底是怎么回事它不再起作用了!
这是正常的。
而且我认为重要的是要知道我们不应该记住所有内容。
这不是要记住所有内容,而是要知道解决方案存在
CSS 中有很多小技巧和窍门,很多很酷的小功能,我无法记住它们是如何工作的,或者说,它们甚至都叫什么!
但是出现了一些事情,而不是想“嗯,我不知道我可以在这里做什么”,而是“哦,我知道有这个东西可以帮助解决这个问题”,然后我立即研究它是什么。也许这是我看到一篇文章或视频的东西,或者也许是我过去使用过的东西,只是忘记了它是如何工作的。
这不是要记住一切是如何运作的。你永远不会那样做。相反,它是关于知道解决方案存在。
你做的事情越多,你越需要使用这些晦涩的功能,你就越会记住它们是如何工作的。然后你将不会使用它 6 个月,你会完全忘记。
这很好。
开源软件的版本

这两天不是React 18[1] duang的一下炸了吗?刚好在了解的过程中看到了React工作组的发布计划[2]
个人觉得是写的很清晰,把不同阶级的版本都进行了说明,在这儿简单说一下每种版本代号的含义。
Apha
内部测试版,主要是针对社区内部人员发布的。α是希腊字母的第一个,表示最早的版本,一般不建议下载这个版本,这个版本包含很多BUG,功能也不全,因为主要是给开发人员和测试人员测试和找BUG用的。
Beta
公开测试版。β是希腊字母的第二个,顾名思义,这个版本在alpha版之后,主要是给一些相关的社区以及忠实的用户测试用的,该版将包含最终版本的所有重大更改和新功能,但是仍然存在一些未发现的BUG,但是相对alpha版要稳定一些。所以还是为了收到反馈并发现任何遗留问题。
如果是负责基础能力的代码大哥们,实在着急的可以开始使用这个版本,主要是测试一下新功能以及升级方面的问题,提前入场准备。
RC
Release Candidate(候选版本),该版本不会再有新增的功能,所以是最接近最终版的版本。该版本的功能已经比较完整和稳定,rc的发布标志着最终版即将到来,rc主要是收集一下版本的稳定性以及用户满意度方面的数据。
这个版本其实一般用户可以下场练手了。
Stable
稳定版。这个就是最终发行版,你可以在里面遨游了。
References
[1] React 18 介绍: https://github.com/reactwg/react-18/discussions/4[2] React 18发布计划: https://github.com/reactwg/react-18/discussions/9
page-lifecycle-api
背景
最近又把前端监控的兴趣提了起来,学习过程中了解到了google的page-lifecycle-api,特此做个记录撒。
https://developers.google.com/web/updates/2018/07/page-lifecycle-api
npm版本锁定
背景
源起于同事找我帮忙排查一个认为诡异的问题。
同样的代码,同样的package.json本地和流水线部署效果不一样。问我可能是什么原因,我当时想到的可能就两种情况:
- 依赖包的版本不一样
- 流水线本身存在问题,比如没有拉到最新的代码?
我简单提供用排除法的思路让她走了一遍,排除了不是最新代码的问题,然后让其对比了一下pacage-lock.json文件,的确发现了依赖包的版本变了,当手动在package.json锁死了本地使用的版本号之后,再执行部署则没有问题。
所以最终问题出在package-lock.json上,那为什么package-lock.json每次跑流水线的时候都会变化呢,是因为流水线脚本里部署前端时脚本里会有:
1.npm clean
2.rm- rf node_modules
3.npm i …等步骤
所以导致每次会更新package-lock.json,那我们提交的package-lock.json就失去了它的价值,即可能每次CI都会有不同版本的包依赖。
经过这次的排查,遂记录一下锁包的个人理解。
开始
package-lock.json
npm 关于package-lock.json的解释说的挺清楚了。主要作用锁定(描述)包依赖关系及其子依赖项。保证对其他开发人员或其他环境安装包的依赖关系一致。
如图:eslint-plugin-react依赖树
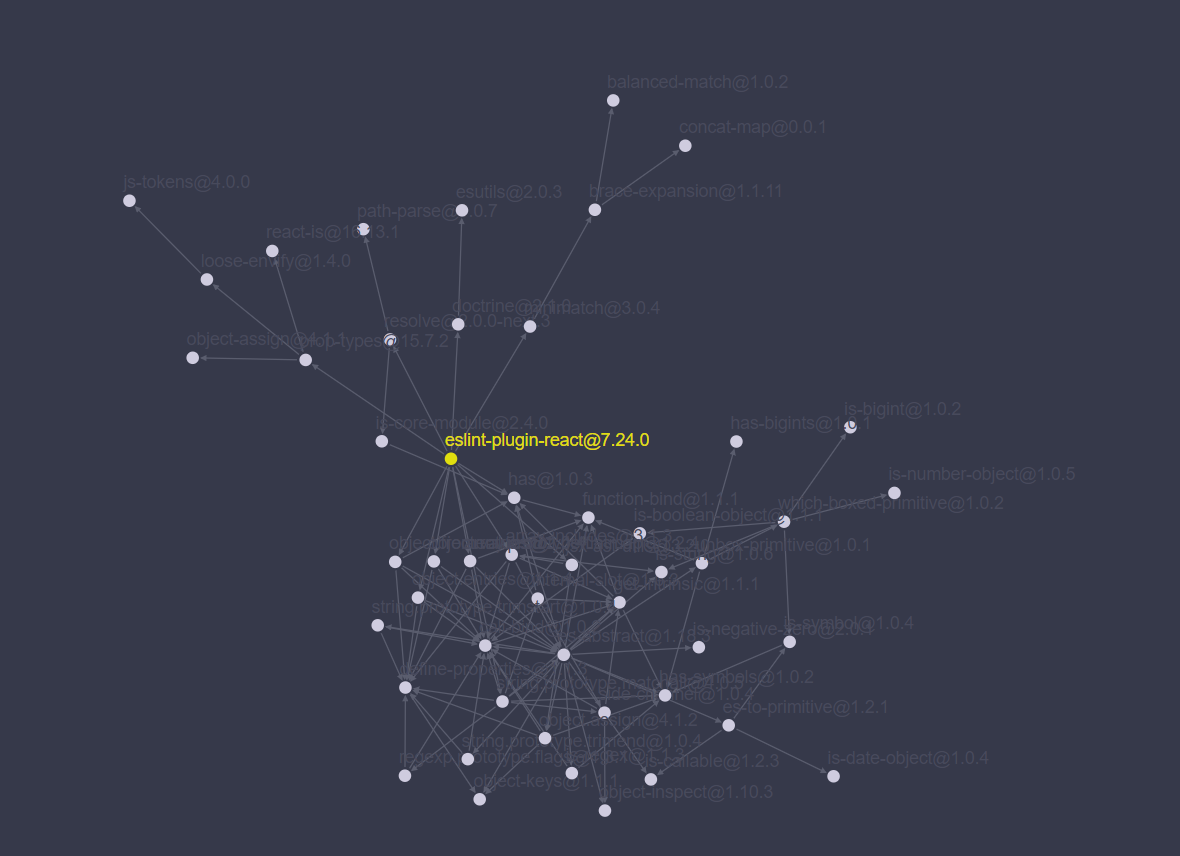
修改node_modules或package.json将自动生成package-lock.json。 它描述了包版本的依赖树,使得后续可以保证无论在哪儿安装能够生成相同的依赖树(也就是相同的包版本),而不管中间依赖性更新如何。
每当我们运行更改依赖项的NPM命令时,如npm i
或npm uninstall 或npm i 等,都将更新包锁定即更新package-lock.json文件。 所以每次提交时必须把package-lock.json也提交到git。
执行npm i 时会读取根据package.json创建的依赖项列表,并使用package-lock.json来通知哪些版本的这些依赖项需要安装。 如果依赖项不在package-lock.json中,它将通过npm i 添加。
根据上面总结的信息,我理解解决上述问题的其中一个方案就是每次CI的时候只需要拉代码之后再npm i 即可,从而保持依赖一致。
npm ci
在深入了解package-lock.json的过程中,npm ci进入了我的视线,详见npm ci。
npm ci(ci:持续集成)直接从package-lock.json安装依赖关系,并使用package.json验证是否存在不匹配的版本。 如果缺少任何依赖项或具有不兼容的版本,则会抛出错误。
因为npm ci是基于package-lock.json进行安装,所以就体现了该命令在包一致性上的作用,在需要重复构建、持续集成等场景下好用。

前提:
必须有package-lock.json文件,即项目第一次初始安装时不能用npm ci,这也说明了为什么上面章节谈到package-lock.json也需要提交到git,这也是原因之一。
所以另一个方案就是每次CI的时候只需要拉代码之后再npm ci 即可,也可保持依赖一致(前提是package.json、package-lock.json每次都进行了同步提交)。
npm i vs npm ci
- npm ci不会更新package-lock.json和package.json,即npm ci 不能更新依赖。
- npm ci必须基于package-lock.json。
- 一般情况下npm ci安装速度会更快。npm ci时如果存在node_modules则会先删除node_modules。
- 初始安装以及更新依赖时,只能使用npm i。
另一个问题:咋个解决package-lock.json冲突
这是一个延申出来的问题,因为需要提交package-lock.json,由于一些原因就可能出现冲突的情况,那咋解决呢?
- 最好别上来就先删除package-lock.json,人是自动生成的没必要跟它较劲。从基线上拉一个package-lock.json文件下来。
- 处理package.json的冲突。
- 执行npm i。
参考:
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。