0%
缩小差距
背景
有些膨胀了,看到了一篇介绍《缩小差距》书的文章,准备对OKR、KPI等企业考核机制做进一步了解,说不定有一天我就平步青云了呢不小心搞个世界500强的管理者当当,到时候可以参考这用用。在这儿做个记录。
前面还是开玩笑的,主要还是身为被考核者,想更深入的了解考核背后的一些东西。虽然内容看上去是从和消费者(顾客)角度来谈绩效,不过我认为其实可以套在公司内部技术团队里,比如上下级对应消费者与服务者的视角?或者反过来?
开始
组织内的各级管理者经常会发现问题,并直接跳到解决方案里去。很多时候,这些方案并不能解决任何问题,这是因为管理者没有找到问题的根本原因。《缩小差距》这本书展现了一个近乎完美的模式,提供一个 无懈可击的思路。你会发现,探究深藏在”现实状况”和”应有水平” 之间差距的原因,是打开最佳解决方案的钥匙。
其实这段内容不太符合我们公司,不是拍马屁,我们公司的管理层最不喜欢直接跳到解决方案里去,平常传递给我们的信息,先找根因,我之前的文章有写。
书中有个高频词语GAPS。
GAPS
GAPS不仅仅是一种模式和策略,它更代表一种全新的企业哲学。把它融入你的管理,你会发现一切变得水到渠成。
决定一个组织成败与否的一个至关重要因素就是人员的绩效。 这里所说的人员包括:工作者、决策者以及与顾客相互接触的人。如果他们能够高质量地完成工作,做出正确的决策,很好地对待顾客,组织就有机会生存,并且有可能兴 旺发达。
有许多因素包括组织的外部和内部因素一一影响人员的绩效。这些因素中,有些具有可控性,有些则是不可控的。
《缩小差距》就是关于如何管理那些可控性因素的。它的主要内容是:如何找到那些对人的工作绩效具有消极影响的因素,并且消除它们。同时,《缩小差距》的内容还包括;用系统的方法揭露并纠正这些因素,以使最 终的影响变得有意义,并且可测量。
每个人的生命中都会有许多美妙的时刻,所有这些时刻,更多的时候,是一种完美。完美是因为,在”现实 状况”和”应有水平”之间没有差距。
在今天飞速变化的商业环境中,管理者在面对问题时,通常是 在没有考虑问题的真正核心的情况下“直接跳到解决方案”。本书将 通过帮助组织中任何层次的人理解”差距战略”并把它应用于工作中, 从而使他们能够避免陷人那些具有破坏性的陷阱。
chapter 1
商业需要=>绩效需要,绩效需要=>工作环境和能力需要。换句话说,你们公司的客户服务代表应该以怎样更多、更好、更与众不同的行动来帮助你实现商业目的。”
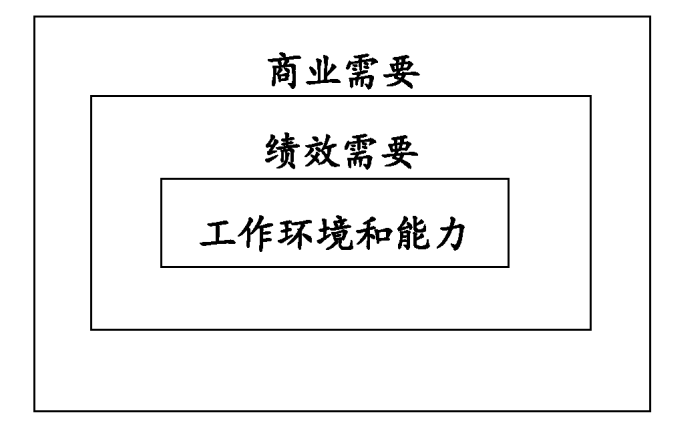
朝〃应有水平’’前进
始终是”更多、更好、更不同” 上
向”应有水平”看齐
向”应有水平”前进
“你得确定’应有水平’是什么。’应 有水平’是你首要的焦点问题,必须为之努力。现在看来,你有两个 ‘应有水平’,
第一个就是我听你说的定额标准:确定标准
第二种是行为的’应有水平:什么是需要做得更多、更好或 更不同的,期望得行为。
做,还是不做
- 问可以自由回答的问题,收集有关消费者故障的信息
- 注意聆听,并且抓住问题的实质
- 基于消费者的情绪或感觉来调整对方的反应
- 在语气上不要表现出争论性,也不要具有攻击性或辩护性
- 在交谈的过程中经常提到顾客的名字
- 看出顾客期望从公司里得到什么,明确说明公司将要采取的行 动
- 提供一个解决问题的切实可行的时间期限
- 表现出耐心并且允许顾客发泄情绪
- 引导交谈重新回到正题轨道上,以缩短整个谈话的长度
- 为任何一个客户服务代表或公司的错误道歉
现实就是差距
目前我们在做的每一件事就 相当于”现实状况” “现实状况”就是差距所在! 分析”现实状况”!
你们不该直接跳到解决方案。相反,你要做的是,比较”现实状况’中的工作 绩效和。应有水平’中的工作绩效,以确定差距所在。”
造成差距的原因
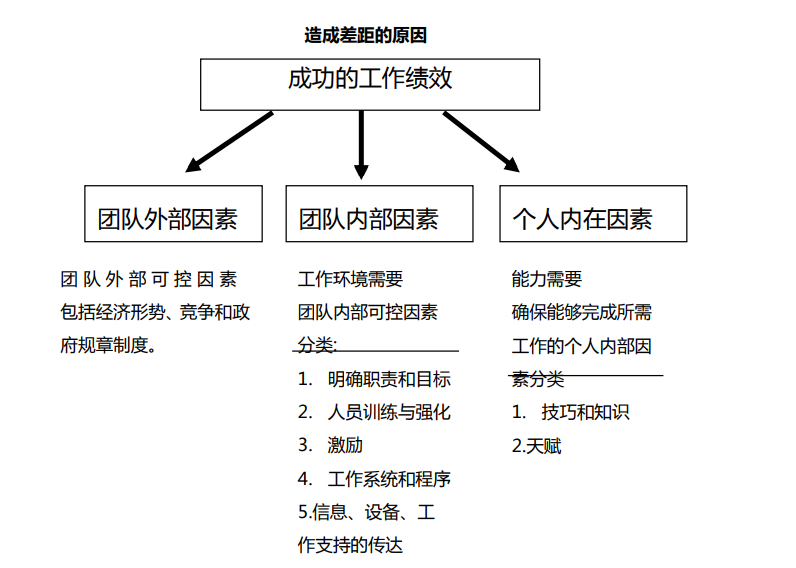
缺少的部分
“这件事用简单的四个字就可以概括:弄清原因。你永远不能、也不可能直接跳到解决方案,你得挖掘原因。很多时候,它们不会直接表露在面上。而是深藏在表皮之下。”

从某些方面来说, 是原因约束了我们。我们曾为了解决问题而苦苦奋斗,而不从实际上 挖掘根本的原因。我们知道了’应有水平’应该是什么样的,并且要组织中心团队来揭露和分析”现实状况”,但是我们却没有弄清楚原因来消除差距。”
对正确的人以正确的方式问正确的问题,你就能够分析’现实状况’并弄清原因。你会很好地缩短’应有水平’和’现实状况’之间的差距。

从原因到解决方案

本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
React Hooks(二)
https://medium.com/geekculture/useimperativehandle-by-examples-99cbdc8e3c3a
Allow me to preface this answer by stating that all of these hooks are very rarely used. 99% of the time, you won’t need these. They are only meant to cover some rare corner-case scenarios.
useImperativeHandle
Usually when you use useRef you are given the instance value of the component the ref is attached to. This allows you to interact with the DOM element directly.
useImperativeHandle is very similar, but it lets you do two things:
It gives you control over the value that is returned. Instead of returning the instance element, you explicitly state what the return value will be (see snippet below).
It allows you to replace native functions (such as blur, focus, etc) with functions of your own, thus allowing side-effects to the normal behavior, or a different behavior altogether. Though, you can call the function whatever you like.
There could be many reasons you want might to do either of the above; you might not want to expose native properties to the parent or maybe you want to change the behavior of a native function. There could be many reasons. However, useImperativeHandle is rarely used.
useImperativeHandle customizes the instance value that is exposed to parent components when using ref
Example
In this example, the value we’ll get from the ref will only contain the function blur which we declared in our useImperativeHandle. It will not contain any other properties (I am logging the value to demonstrate this). The function itself is also “customized” to behave differently than what you’d normally expect. Here, it sets document.title and blurs the input when blur is invoked.
Show code snippet
useLayoutEffect
While similar to some extent to useEffect(), it differs in that it will run after React has committed updates to the DOM. Used in rare cases when you need to calculate the distance between elements after an update or do other post-update calculations / side-effects.
The signature is identical to useEffect, but it fires synchronously after all DOM mutations. Use this to read layout from the DOM and synchronously re-render. Updates scheduled inside useLayoutEffect will be flushed synchronously, before the browser has a chance to paint.
Example
Suppose you have a absolutely positioned element whose height might vary and you want to position another div beneath it. You could use getBoundingCLientRect() to calculate the parent’s height and top properties and then just apply those to the top property of the child.
Here you would want to use useLayoutEffect rather than useEffect. See why in the examples below:
With useEffect: (notice the jumpy behavior)
Show code snippet
With useLayoutEffect:
Show code snippet
useDebugValue
Sometimes you might want to debug certain values or properties, but doing so might require expensive operations which might impact performance.
useDebugValue is only called when the React DevTools are open and the related hook is inspected, preventing any impact on performance.
useDebugValue can be used to display a label for custom hooks in React DevTools.
I have personally never used this hook though. Maybe someone in the comments can give some insight with a good example.
前端深似海
把我知乎回答的一篇文章拿过来。
背景
人到30总想多做点什么,不然怕被干趴下了,毕竟不能被干趴下,所以就写写说说,万一走上一条不归路呢,那多刺激。
第一篇知乎文章啊 就给了前端,可见爱的多么深沉。
前几年除了迷茫时期浪的其他行业,都是在做后端,最近这两年由于公司当时的业务需要赶鸭子上架写起了前端代码,对于当时只会一点js和html以及削微一点点css的我来说,那是酸爽的一比啊。
一入前端深似海啊深似海。
因为我属于半路出家,所以没有系统性的学习,我只能在这儿随便抒发我的游击路线。
如果你着急
先找个视频根据自己的需要搭建好本地环境。
这个时候就别再想着拿本恁厚的犀牛书或者JavaScript高级程序设计等等书来啃了,因为来不及,我的建议是边做边学,先让自己动起来。
- 找学习内容
网上一大堆学习网站和博客,所以其实这个时候你会发现你最需要的是掌握搜索技巧。首先尽量别用百度搜索,体验太差,可以用必应或者最近比较火的夸克之类的。
我的建议是如果不能访问外网,就尽量到垂直领域类的网站去搜索,比如github、开源中国、博客园等,以及一些视频网站比如网易公开课,这里特别要注意github,它可是个宝藏啊,啥都有。
如果实在找不到质量好的课程最简单的方法就是花钱,现在网上各种课程一大堆,首先能确定一点能开课且还收钱的肯定有两把刷子最起码比你强,那你花点钱不冤枉。这个时候尽量挑实操性强的有针对性的课程,讲原理、扩展类的就先别接触了。
- 学习方式
边学边跟着练。要多练不停的练,想不明白甚至照着敲几遍都行。
如果有必要可以边学边写工作代码,不要怕先干起来。当然前提有几点:
- 首先你可以放心一点:除非你们的系统是PPT或者KPI系统,不然是没人敢放你写代码的,所以人给了机会你就得先迈一步,没事走两步。
- 团队有code review,找大牛给你code review,你会成长得很快。这个时候就别要脸了。你根本没脸,不要问我咋知道得。
- 不要一开始就写核心业务代码,当然也几乎不可能让你上。
- 做好对当前代码会不断重构的心理准备。
这个时候还有个东西很重要,那就是工具,提效的工具。
代码规范
Gamehu:Lint工具zhuanlan.zhihu.com Lint笔记-ESLintgamehu.run
Lint笔记-ESLintgamehu.run
代码调试
Chrome Tools-Sourcesgamehu.run
如果你不着急
可以先看看这个
Front-end web developerdeveloper.mozilla.org
目标
整个系统性的学习框架出来,如果自己搞出来有难度,很简单随便上网用关键字搜一下,比如搜面试指南、前端技术雷达、前端知识框架、前端技术思维导图等然后把你搜索到的内容对比一下,基本上就能知道你需要在不同阶段掌握哪些内容了。
总之先整个可量化的内容以及明确的目标出来。
目标要阶段性且有挑战性且可给与你反馈的。
然后可能需要这么干:
- 从基础类内容开始学起。比如HTML、CSS、ES6等
可能很多时候当人开始准备做前端的时候,就有一种冲动选择像React、Bootstrap、AntD等流行的库或者框架,并开始投入大量时间到基于它们构建的内容中。
这是不明智的,你要控zhi你自己。 如果不了解基础知识,就永远无法使用这些主流框架更高级的特效以及创建更高级的项目。 要记住不积硅步无以至千里啊,盆友们。
- 应用
注意,学习和应用之间存在巨大差异。
从0开始,使用HTML / CSS / JavaScript创建一个小型但有效的项目。 然后,不断的一个又一个的创建练习的项目。
在此过程中,不断增加项目的复杂性和期望值,直到达到你设定的目标。这个时候你再考虑拿一些主流的库和框架来联手了,深刻理解“造轮子”这个词。
- 看书
书那就太多了,这个时候你应该大体对前端有一定的认知,这个时候你就可以选书看看了,我不太爱看书啊,一看书就打瞌睡,所以看书慢且比较少,所以看个人了,下面是我看的部分书。有机会后续会把书单完整列一个。另外如果喜欢电子书可以买个阅读器,市面上茫茫多,我自己是几年前买了个Kindle上面的书比我纸质书多。
[《Web开发经典丛书:HTML & CSS 设计与构建网站》(美]Jon Duckett)【摘要 书评 试读】- 京东图书item.jd.com [《JavaScript高级程序设计 第4版(图灵出品)》(美]马特·弗里斯比(Matt,Frisbie))【摘要 书评 试读】- 京东图书item.jd.com
[《JavaScript高级程序设计 第4版(图灵出品)》(美]马特·弗里斯比(Matt,Frisbie))【摘要 书评 试读】- 京东图书item.jd.com
 我的一部分…
我的一部分…
- 看源码
先别直接上来就看React等源码,相信我你可能会自闭的。
找一些基础的库比如lodash等看看源码,你会印证和学到很多。
循序渐进,弄清楚一些主流的框架为什么要这么做。有时候,直接使用某些框架可能并不是最好的选择,但是在大多数情况下,了解它们是没错的。
- 了解工具
在开始前端开发的过程中,了解不同的工具选项是很重要的。 出色的工具应用将让你的更加的得心应手。
Chrome Tools、git、npm、webpack、node、postman、nginx等,其中chrome tools、git、nginx我个人认为熟练掌握很重要。
- 用户体验
这其实属于软技能了,需要一种思维的转变。
做一个好用的产品。
作为前端开发人员,需要意识到自己处于某种中间人角色。 作为中间人,与QA人员,产品,UCD以及其他开发人员都会有交集。你将需要考虑不同的观点。在这个过程中你会发现你可能会做了一些产品、UCD等角色的工作。
始终保持良好的用户体验不仅是从用户的角度,还是从其他开发人员的角度。
- 参加开源项目
这块好处那就多了,成就感、能力提升、献出自己的一份力、结交新朋友等等
这个是我一直的痛,个人能力有限吧,或者说没找到入门的方式或者说懒,我迟迟没有跨出这一个步…我也要加油了
小结
暂时写这么多吧,感觉如果还不收手的话,写一个星期的写不完,因为其实里面的很小一个点估计也能写好多文字,前端为什么深似海就是因为轮子太多,技术栈更新快,前端地位愈发重要等等。
我跟你们放一张图你们就明白深似海,我为何感慨了。
这张图就是现在我主要下手的内容,这只是前端工程化部分的内容,已经够够够学好久了。。。
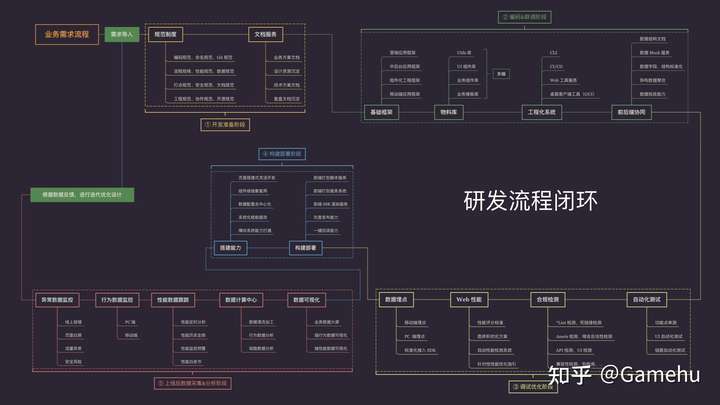
很抱歉我确实忘记是从哪儿看到的的图了,如果有侵权请联系我删除,由此给您带来的困扰我十分抱歉。
另外说一下如果要报课程,我建议大家还是慎重,毕竟现在市面上各类培训或者课程太多,别挑花眼的同事把自己整的太浮躁,一口吃不成胖子。我还是提倡实操为主,直接找公司实习,不要钱都行。
如果非要报,报个系统性的线上或者线下课程,最好是选择学习时能直接产生交互或者反馈的那类课程,最好不要录播的。
Tools for Auditing CSS(CSS检查工具)
背景
之前关注比较多的还是js以及js扩展语言方面的检测工具,对css方面的检查工具了解较少,个人感觉css的检查确实比较难。刚好这两天看到了一篇css检查工具的文章,刚好蹩脚的翻译一下,做个记录。
就如文中作者所说,当然自身也有体会,css检查一个很大的难点就是:可以通过许多不同的方式来实现相同的样式。这已经就让CSS审核起来有些棘手。
通过之前我在团队内分享的stylelint等工具可以避免一些问题,但是其实是不够的。仍然还有一些问题时无法解决的比如:太多的颜色,排版或z-indexs。
所以作者给我们列举了一些工具,用于检查css。
开始
浏览器内的开发工具
用Chrome DevTools 的 CSS 检查工具举例。 详细的可参考 Umar Hansa 的这篇文章 —Chrome一大堆发布于 2020 年的「伟大的」 DevTool 功能。
如果你喜欢手动检查 CSS 代码,我们可以使用 Inspect 工具以找出应用于特定元素的 CSS 代码。使用 “Inspect arrow”,我们甚至可以看到关于颜色、字体、大小和可访问性的那些额外的细节。
Grid 和 Flex 的检查器
DevTools 界面中有很多实用的工具,我最喜欢的是 Grid 和 Flex 检查器。要启用它们,请进入设置(DevTools 右上方的一个小齿轮图标),点击 Experiments,然后启用 CSS Grid 和 Flexbox 调试功能。虽然这个工具主要用于调试布局问题,但我有时也会用它来快速判断页面上是否使用了 CSS Grid 或 Flexbox。
CSS Overview
让我们看看一些更高级的 DevTools 功能。CSS Overview 就是其中之一。
要启用 CSS Overview 工具,进入设置,点击 Experiments,启用 CSS Overview 选项。
要打开 CSS Overview 面板,我们可以使用 ⌘ ⇧ P 或 Ctrl ⇧ P 快捷键,输入 css overview,然后选择 Show CSS Overview。这个工具可以展现 CSS 属性的概览,比如颜色、字体、对比度问题、未使用的声明和media查询。我通常用这个工具来判断当前 CSS 代码的好坏。例如,如果有 50 种灰度色彩或过多的排版定义,就意味着样式规范没有被应用到实际,或者甚至可能不存在样式规范。
不过请注意,该工具会对应用于这个页面的样式做出概览,而不是对单个文件做出概览。
Coverage panel
Coverage Panel 工具会显示页面上使用的代码数量和百分比。要查看它,我们可以使用 ⌘ ⇧ P 或 Ctrl ⇧ P 快捷键,键入 Coverage,选择 Show Coverage,然后点击刷新图标。
你可以在 URL 过滤器中输入 .css 以用于过滤专门显示 CSS 文件。我通常使用这个工具来了解网站的交付技术。例如,如果我看到 CSS 的覆盖率相当的高,我就可以认为 CSS 文件是为每个页面单独生成的。这可能不是关键数据,但有时它有助于了解缓存策略。
Rendering Panel
Rendering Panel 是另一个有用的工具。要打开渲染面板,我们可以使用 ⌘ ⇧ P 或 Ctrl ⇧ P 快捷键。这次输入 “Rendering”,然后选择 “Show Rendering” 选项。这个工具有很多选项,个人觉得最好用的是:
- Paint flashing — 当重绘事件发生时会显示绿色矩形。我用它来识别需要花费太多渲染时间的区域。
- Layout Shift Regions — 当布局移动发生时显示蓝色矩形。为了充分利用这些选项,我通常在 “网络” 选项卡下设置 “Slow 3G” 预设。我有时会录制我的屏幕,然后放慢视频速度来寻找布局转移。
- Frame Rendering Stats — 显示 GPU 和帧的实时使用情况。这个工具在识别动画卡顿和滚动问题时很方便。
这些工具会给出常规检查中没有的数据,它对于了解 CSS 代码是否具有性能以及消耗设备的能量的多少提供依据。
其他选项可能对调试问题更有利,比如模拟和禁用各种功能,强制使用 prefers-color-scheme 功能或打印媒体类型,以及禁用本地字体。
Performance Monitor
另一个检查 CSS 代码性能的工具是 Performance Monitor。要启用它,我们可以使用 ⌘ ⇧ P 或 Ctrl ⇧ P 快捷键,输入 Performance Monitor,然后选择 Show Performance Monitor 选项。我通常使用这个工具来查看与页面交互或动画发生时会触发多少次重新计算和布局。
Performance Panel
在 Performance Panel 上,我们可以详细查看页面加载过程中的所有浏览器事件。要启用性能工具,我们可以使用 ⌘ ⇧ P 或 Ctrl ⇧ P 快捷键,输入 Performance,选择 Show Performance,然后点击 “重新加载” 图标。我通常会启用 Screenshots 和 Web Vitals 选项。对我来说,最感兴趣的是First Paint、 First Contentful Paint、Layout Shifts、 Largest Contentful Paint这几个指标。
还有一个饼图显示了绘制和渲染时间。
DevTools 可能不算是一个经典的检查工具,但它可以帮助我们了解哪些 CSS 功能被使用,代码的效率,以及代码的执行情况,而这些都是 CSS 代码检查的关键所在。
在线工具
DevTools 只是用于检查css的其中一个工具,下面介绍一下其它可用来检查 CSS 代码的工具:
Specificity Visualizer
Specificity Visualizer显示代码库中 CSS 选择器的特殊性。只需访问网站并粘贴 CSS。
主图 Main Chart 会显示特定样式与样式表中的位置的关系。另外两个图表显示了特定样式的使用情况。我经常使用这个网站来寻找 “bad” 选择器。例如,如果我看到许多特定样式被标记为红色,我很容易得出结论 —— 这里的 CSS 代码可以改进得更好。在你努力改进时,保存截图以供参考是很有帮助的。
CSS Specificity Graph Generator
CSS Specificity Graph Generator是一个类似的可视化特定样式工具。它显示了一个略有不同的图表,可能会帮助你看到你的 CSS 选择器是如何按特定样式组织的。正如它在工具页面上所说的那样,”波峰是不好的,总的趋势应该是在样式表的后期有更高的特定样式”。进一步讨论这个问题会很有意思,但这不在本文的讨论范围内。然而,Harry Roberts 在他的文章 “The Specificity Graph” 中确实广泛地写到了这一点,值得一试。
CSS Stats
CSS Stats 是另一个为你的样式表提供分析和可视化的工具。事实上,Robin 在不久前写过关于它的文章,并展示了他如何使用它来审核他工作中的样式表。
你需要做的就是输入网站的 URL,然后点击 Enter。这些信息被分割成有意义的部分,包括了样式的声明数、颜色、排版、z-index 和特定样式等等。同样,你可能要把截图存储起来,以备日后参考。
Project Wallace
Project Wallace 是由 Bart Veneman 开发的,而他已经在 CSS Tricks 上介绍了这个项目。Project Wallace 的强大之处在于,它可以比较和可视化基于导入的变化。这意味着你可以看到你的 CSS 代码库以前的状态,并看到你的代码在不同状态之间的变化。我觉得这个功能相当有用,特别是当你想说服别人代码是改进过的。该工具对单个项目是免费的,并为更多项目提供付费计划。
CLI 工具
除了 DevTools 和在线工具,还有命令行界面(CLI)工具可以帮助我们检查 CSS:
Wallace
我最喜欢的 CLI 工具之一是Wallace。安装后,输入wallace,然后输入网站名称,它就会自动输出显示了你需要知道的关于网站的 CSS 代码的一切。我最喜欢看的是 !important 的使用次数,以及代码中有多少个 ID。另一个信息是顶级特定样式的数量以及有多少选择器使用它。这些可能是 “坏” 代码的危险信号。
我最喜欢这个工具的地方是,它可以从网站中提取所有的 CSS 代码 —— 不仅是外部文件,还能够包括内联代码。这就是为什么 CSS Stats 和 Wallace 的报告不匹配的原因。
csscss
csscss CLI 工具可以显示哪些规则共享相同的声明,而这对于识别重复的代码和减少编写的代码量是很有用的。在这样做之前,我会三思而后行,因为这可能是不值得的,尤其是在今天的缓存机制下。值得一提的是,csscss 需要 Ruby 运行环境。
其他有用的工具
- Color Sorter — 先按色调,再按饱和度对 CSS 颜色进行排序。
- CSS Analyzer — 对一串 CSS 进行分析。
- constyble — 这是一个基于 CSS Analyzer 的 CSS 复杂性分析器。
- Extract CSS Now — 从一个网页中获取所有 CSS。
- Get CSS — 从一个网页中获取所有的 CSS。
- uCSS — 抓取网站以识别未使用的 CSS。
结语
CSS在我们周围无处不在,我们需要将其视为每个项目的头等公民。 如果您的CSS井井有条且编写精良,那么您将花费更少的时间调试它,而将更多的时间用于开发新功能。 在理想的世界中,我们会训练每个人都编写出色的CSS,但这需要时间。
今天是开始关心CSS代码的日子。
我知道审核CSS对每个人都不会很有趣。 但是,如果您针对这些工具中的任何一个运行代码,并尝试甚至改善CSS代码库的一部分,那么这篇文章就完成了它的工作。
最近,我越来越多地考虑CSS代码,并且试图使更多的开发人员更加尊重CSS代码。 我甚至开始了一个新项目css-auditors.com,该项目专门用于审核CSS。
度量DevOps四个关键指标

交代
最近看了篇Google出的关于DevOps的文章《度量DevOps四个关键指标》,在这儿做个记录。google翻译+蹩脚的自我理解,莫吐槽,将就看。
开始
通过六年的研究,DevOps研究与评估(DORA)团队确定了四个关键指标,这些指标指示了软件开发团队的绩效:
- 部署频率 - 成功发布产品的频率。
- 变更前置时间 - 变更从提交到发布所需要的时间
- 变更失败率 - 发布失败次数在部署中的占比
- 恢复服务的时间 - 从生产故障中恢复需要多长时间
变更的部署频率和变更前置时间可以衡量速度,变更失败率和恢复服务的时间可以衡量稳定性。通过衡量这些价值,并不断进行迭代来改进它们,团队可以取得更好的业务成果。
然后说了一下google cloud的做法。后面跟google cloud提供的服务有关的就不翻译文字了。

指标计算
本节讨论如何将DORA度量标准转换为系统级计算。DORA团队所做的原始研究是对真实的人进行调查,而不是收集系统数据并将指标存储到性能级别中,如下所示:

部署频率
1 | 一个组织成功地部署到生产环境的百分比。 |
部署频率是最容易收集的指标,因为它只需要一个表。但是,频率存储也是要计算的棘手元素之一。显示每日部署数量或每周获取平均部署数量将很简单明了,但指标是部署频率,而不是数量。
在“Four Keys”脚本中,当每周至少进行一次成功部署的中位数天数等于或大于三时,“部署频率”将落入“每日”时段。简而言之,要想部署频率值为“每日一次”,则必须在大多数工作日进行部署。同样,如果大多数部署都是一星期一次,则将是每周一次,然后是每月一次,依此类推。
接下来,则需要考虑是基于哪些原因及资源构成了成功的生产部署。您是否包括仅占5%流量的部署?80%?默认情况下,仪表板包括任何成功部署到任何级别的流量。
变更前置时间
1 | 一次提交进入生产环境所花费的时间。 |
“变更前置时间”度量标准需要两个重要的数据:何时发生提交和何时进行部署。这意味着对于每个部署,需要维护对应的更改的列表。使用部署表中的更改列表,每次数据的重新加入时同时获取相应的时间戳,用于计算中位数。
变更失败率
1 | 用于生产环境部署失败的百分比 |
变更失败率取决于两件事:尝试了多少次部署,多少次导致生产部署失败?
恢复服务的时间
“组织从生产故障中恢复需要多长时间”
要测量恢复服务的时间,您需要知道事件的创建时间和解决时间。还需要知道何时发生故障以及何时部署解决了该故障。与上一个指标类似,此数据可以来自任何故障管理系统。
仪表板
这个就不多说了。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
数字化

看到DXCon一篇文章,做个记录
怎么理解数字化转型?
优化是通过把你的服务线上化,减少摩擦,提供更好的服务体验。
那数字化转型真正转的应该是什么?
数字化转型,最终转的是客户价值的创造。
通过数字化智能化的方式,使原来没有办法传递的价值,现在可以传递出去。最终的目的是创造一种模式,不管是商业模式,还是运营模式,使得能够颠覆原来没办法做到的事情,或者是原来很难做到的事情。通过数字化来达成原来不可能达成的价值创造的一种方式,最终的核心应该是要创造价值。
通过数字化来达成原来不可能达成的价值创造的一种方式,就是数字化最终的目的应该是要创造价值。
最后来句废话
我从参加工作开始几乎都是在ToB行业,刚好有两家公司就是干数字化转型的,我一开始的理解不过是从纸质媒介转到网络媒介,从线下到线上,实操经验告诉我,最终看的还是为用户创造了哪些价值,实用为主的客户你跟他扯概念鸟用没有。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。